Crash Course Computer Science【计算机科学速成课】(4)
感谢速成课!感谢 Carrie Anne!感谢中文翻译组!~
原视频
Crash Course Computer Science
https://github.com/1c7/crash-course-computer-science-chinese
第 31 集 计算机安全
计算机安全可以看成是保护系统和数据的:保密性,完整性和可用性,保密性”是只有有权限的人才能读取计算机系统和数据,黑客泄露别人的信用卡信息,就是攻击保密性。”完整性”是只有有权限的人才能使用和修改系统和数据,黑客知道你的邮箱密码,假冒你发邮件就是攻击”完整性”。”可用性”是有权限的人应该随时可以访问系统和数据,拒绝服务攻击(DDOS) 就是黑客,发大量的假请求到服务器,让网站很慢或者挂掉。
为了实现这三个目标,安全专家会从抽象层面想象”敌人”可能是谁,这叫”威胁模型分析“。模型会对攻击者有个大致描述:能力如何,目标可能是什么,可能用什么手段,攻击手段又叫”攻击矢量“。”威胁模型分析”让你能为特定情境做准备,不被可能的攻击手段数量所淹没,因为手段实在有太多种了。
通常威胁模型分析里会以能力水平区分,在给定的威胁模型下,安全架构师要提供解决方案,保持系统安全。很多安全问题可以总结成2个问题:你是谁?你能访问什么?为了区分谁是谁,我们用 “身份认证“(authentication)让计算机得知使用者是谁。
身份认证有三种,各有利弊:你知道什么,你有什么,你是什么。”你知道什么” 是基于某个秘密,比如用户名和密码。”你有什么”这种验证方式,是基于用户有特定物体,比如钥匙和锁。”你是什么”这种验证,是基于你把特征展示给计算机进行验证,生物识别验证器,比如指纹识别器和虹膜扫描仪就是典型例子。
所有认证方法都有优缺点,所以,对于重要账户,安全专家建议用两种或两种以上的认证方式,这叫”双因素”或”多因素”认证。
一旦系统知道你是谁,它需要知道你能访问什么,因此应该有个规范,说明谁能访问什么,修改什么,使用什么。这可以通过”权限”或”访问控制列表“(ACL)来实现,描述了用户对每个文件,文件夹和程序的访问权限。如果用户等级是”绝密“,那么能写入或修改”绝密”文件,但不能修改”机密”或”公共”文件,听起来好像很奇怪有最高等级也不能改等级更低的文件,但这样确保了”绝密”不会意外泄露到”机密”文件或”公共”文件里。这个”不能向上读,不能向下写”的方法叫 Bell-LaPadula 模型。它是为美国国防部”多层安全政策”制定的,还有许多其他的访问控制模型比如”中国墙”模型和”比伯”模型。
我们无法保证程序或计算机系统的安全,因为安全软件在理论上可能是”安全的”,实现时可能会不小心留下漏洞,但我们有办法减少漏洞出现的可能性。比如一找到就马上修复,以及当程序被攻破时尽可能减少损害。当程序被攻破后,如何限制损害,控制损害的最大程度,并且不让它危害到计算机上其他东西,这叫”隔离“。要实现隔离,操作系统会把程序放到沙盒里,方法是给每个程序独有的内存块,其他程序不能动,虚拟机模拟计算机,每个虚拟机都在自己的沙箱里,如果一个程序出错,最糟糕的情况是它自己崩溃,或者搞坏它处于的虚拟机,计算机上其他虚拟机是隔离的,不受影响。
第 32 集 黑客 & 攻击
黑客入侵最常见的方式不是通过技术,而是欺骗别人,这叫”社会工程学“,欺骗别人让人泄密信息或让别人配置电脑系统,变得易于攻击,最常见的攻击是网络钓鱼。银行发邮件叫你点邮件里的链接,登陆账号,然后你会进入一个像官网的网站,但实际上是个假网站,当你输入用户名和密码时,信息会发给黑客,然后黑客就可以假扮你登陆网站。
另一种方法叫 **假托(Pretexting)**,攻击者给某个公司打电话,假装是IT部门的人,攻击者的第一通电话一般会叫人转接这样另一个人接的时候,电话看起来像内部的,然后让别人把电脑配置得容易入侵,或让他们泄露机密信息,比如密码或网络配置。邮件里带”木马“也是常见手段,木马会伪装成无害的东西,比如照片或发票,但实际上是恶意软件。有的会偷数据,比如银行凭证,有的会加密文件,交赎金才解密,也就是”勒索软件“。
最近出现一种攻破方法叫 “NAND镜像“,如果能物理接触到电脑可以往内存上接几根线,复制整个内存,复制之后,暴力尝试密码,直到设备让你等待,这时只要把复制的内容覆盖掉内存,本质上重置了内存,就不用等待,可以继续尝试密码了。如果你无法物理接触到设备就必须远程攻击,比如通过互联网,远程攻击一般需要攻击者利用系统漏洞来获得某些能力或访问权限,这叫”漏洞利用“(Exploit),一种常见的漏洞利用叫”缓冲区溢出“。有很多方法阻止缓冲区溢出,最简单的方法是,复制之前先检查长度,这叫 “边界检查“。许多现代编程语言自带了边界检查,程序也会随机存放变量在内存中的位置,这样黑客就不知道应该覆盖内存的哪里,导致更容易让程序崩溃,而不是获得访问权限。程序也可以在缓冲区后,留一些不用的空间,然后跟踪里面的值,看是否发生变化,如果发生了变化,说明有攻击者在乱来。这些不用的内存空间叫”金丝雀“,因为以前矿工会带金丝雀下矿,金丝雀会警告危险。
另一种经典手段叫”代码注入“,最常用于攻击用数据库的网站,几乎所有大网站都用数据库。”结构化查询语言“,也叫SQL,一种流行的数据库API,假设网页上有登录提示,当用户点击”登录”时,值会发到服务器,服务器会运行代码,检查用户名是否存在,如果存在,看密码是否匹配。为了做检查,服务器会执行一段叫 “SQL查询“ 的代码。
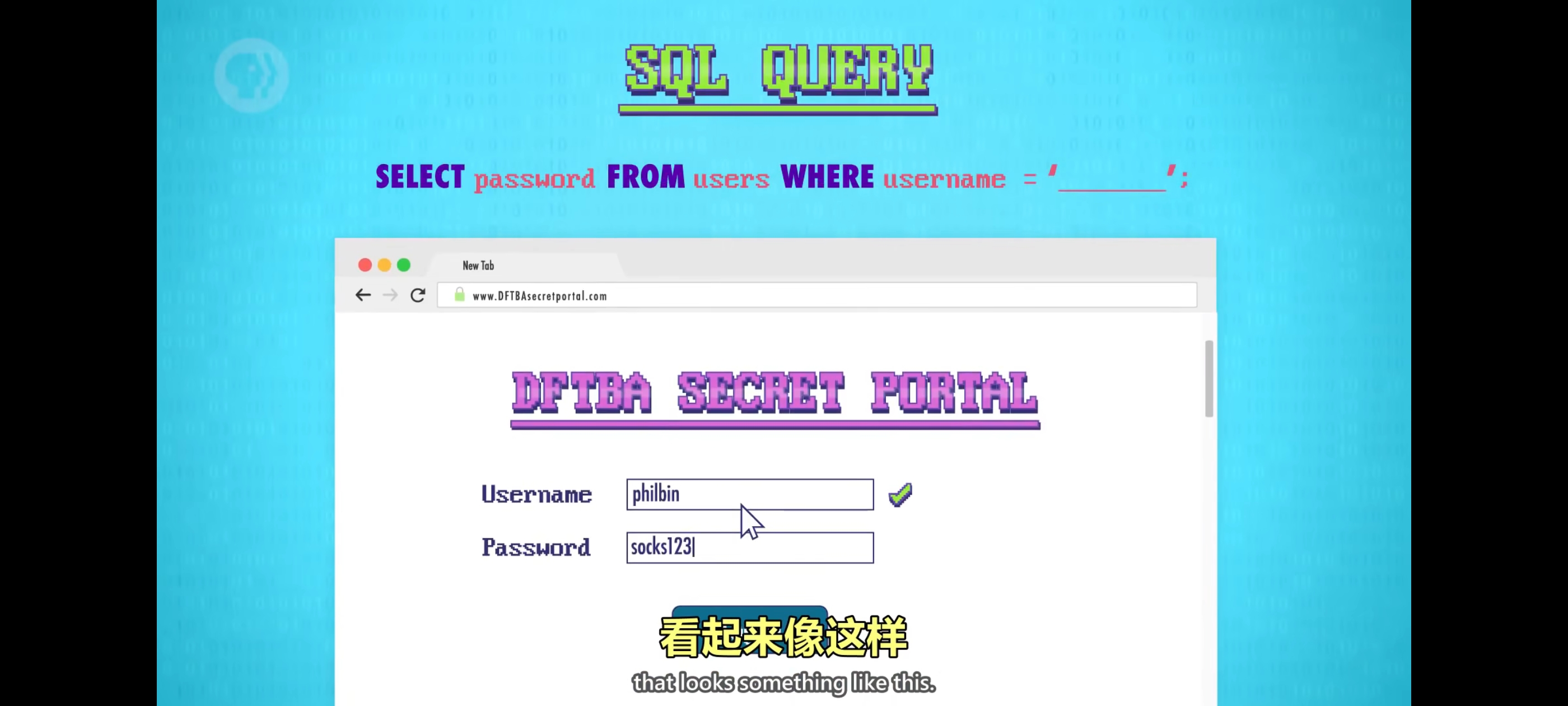
首先,语句要指定从数据库里查什么数据,还要指定从哪张表查数据,假设所有用户数据都存在 “users” 表里,最后,服务器不想每次取出一个巨大密码列表,包含所有用户密码,所以用 username = ‘用户名’代表只要这个用户。用户输的值会复制到”SQL查询”,实际发到 SQL 数据库的命令是where username=’philbin’,SQL命令以分号结尾。注入命令 drop table users ,删掉 users 这张表,我们甚至不需要侵入系统,没有正式访问权限,还是可以利用 bug 来制造混乱。
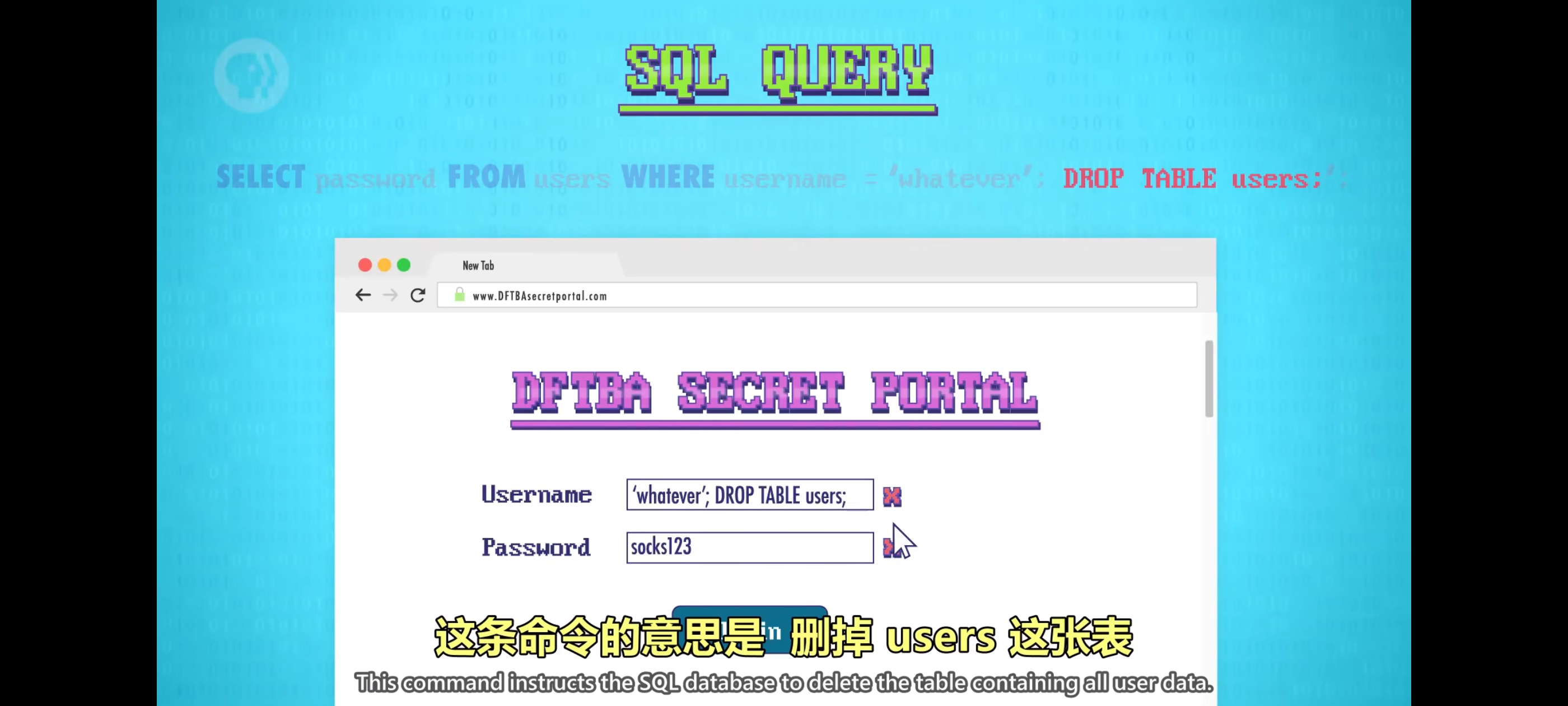
这是代码注入的一个简单例子,如今几乎所有服务器都会防御这种手段,如果指令更复杂一些,也许可以添加新记录到数据库,甚至可以让数据库泄露数据,使得黑客窃取信用卡号码,社会安全号码,以及各种其他信息。
如果有足够多的电脑有漏洞让恶意程序可以在电脑间互相传播,那么叫”蠕虫“,如果黑客拿下大量电脑,这些电脑可以组成”僵尸网络“。
第 33 集 加密 Cryptography
密码学(cryptography)一词来自 crypto 和 graphy,大致翻译成”秘密写作”,为了加密信息,要用加密算法(Cipher) 把明文转为密文,这叫”加密”(encryption),把密文恢复回明文叫”解密”(decryption)。
“凯撒加密“把信件中的字母向前移动三个位置,所以A会变成D,brutus变成euxwxv,为了解密,接收者要知道1. 用了什么算法 2. 要偏移的字母位数,有一大类算法叫”替换加密“,凯撒密码是其中一种。算法把每个字母替换成其他字母,但有个巨大的缺点是,字母的出现频率是一样的,熟练的密码破译师可以从统计数据中发现规律,进而破译密码。另一类加密算法叫 “移位加密“,把明文填入网格,为了加密信息换个顺序来读,比如从左边开始,从下往上,一次一列,加密后字母的排列不同了,解密的关键是,知道读取方向和网格大小。
到了1900年代,人们用密码学做了加密机器,其中最有名的是德国的英格玛(Enigma),纳粹在战时用英格玛加密通讯信息,一台像打字机的机器,有键盘和灯板,两者都有完整的字母表,而且它有一系列”转子“(rotros) ,是加密的关键。可以按不同顺序放入转子,提供更多字母替换映射,转子之后是一个叫”反射器“的特殊电路,它每个引脚会连到另一个引脚并把信号发回给转子,机器前方有一个插板可以把输入键盘的字母预先进行替换,又加了一层复杂度。
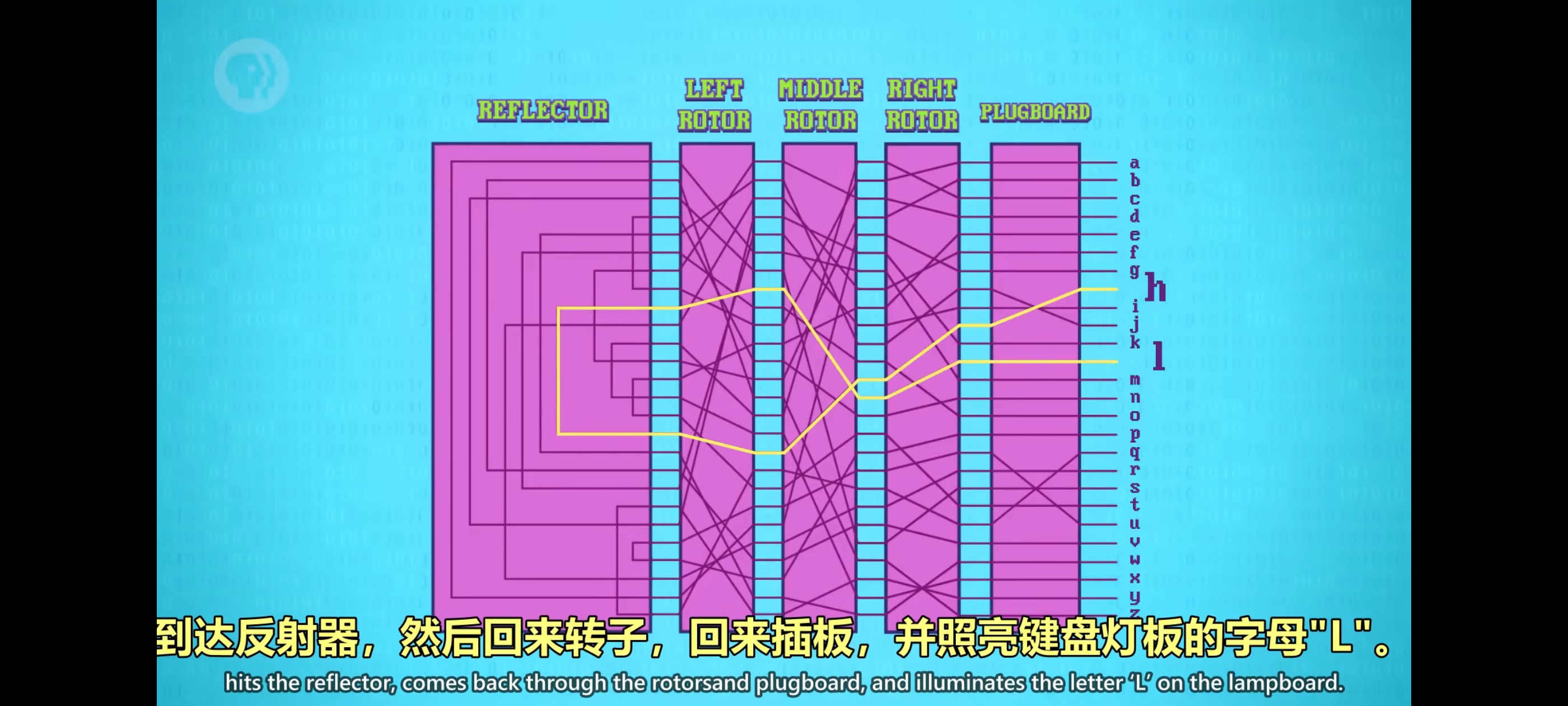
为了让英格玛不只是简单的”替换加密”,每输入一个字母,转子会转一格,有点像汽车里程表。映射会随着每次按键而改变,但艾伦·图灵和同事破解了英格玛加密,并把大部分破解流程做成了自动化。
早期加密算法中,应用最广泛的是 IBM 和 NSA 于1977年开发的”数据加密标准“,DES最初用的是56 bit长度的二进制密钥,意味着有2的56次方,或大约72千万亿个不同密钥。但到1999年,一台25万美元的计算机能在两天内把 DES 的所有可能密钥都试一遍,让 DES 算法不再安全。因此 2001 年出了:高级加密标准(AES)用更长的密钥 - 128位/192位/256位。AES将数据切成一块一块,每块16个字节,然后用密钥进行一系列替换加密和移位加密,再加上一些其他操作,进一步加密信息,每一块数据,会重复这个过程10次或以上。AES 在性能和安全性间取得平衡,如今AES被广泛使用,比如iPhone上加密文件,用 WPA2 协议在 WiFi 中访问 HTTPS 网站。
密钥交换是一种不发送密钥,但依然让两台计算机在密钥上达成共识的算法。用 “迪菲-赫尔曼密钥交换“,其中单向函数是模幂运算,意思是先做幂运算,拿一个数字当底数,拿一个数字当指数,然后除以第三个数字,最后拿到我们想要的余数。
首先,我们有公开的值 - 基数和模数,为了安全向 John 发信息,我选一个秘密指数:X,然后把这个大数字发给 John。John 也一样做,选一个秘密指数Y,然后把 B^Y mod M 的结果发我。为了算出 双方共用的密钥,我把 John 给我的数,用我的秘密指数 X,进行模幂运算,数学上相等于 B的XY次方模M,John也一样做,拿我给他的数进行模幂运算,最终得到一样的数。

双方有一样的密钥,即使我们从来没给对方发过各自的秘密指数,我们可以用这个大数字当密钥,用 AES 之类的加密技术来加密通信。
双方用一样的密钥加密和解密消息,这叫”对称加密“, 因为密钥一样,还有”非对称加密“,有两个不同的密钥一个是公开的,另一个是私有的,人们用公钥加密消息只有有私钥的人能解密,知道公钥只能加密但不能解密。这种做法用于签名,服务器可以用私钥加密,任何人都可以用服务器的公钥解密,就像一个不可伪造的签名,因为只有私钥的持有人能加密,这能证明数据来自正确的服务器或个人,而不是某个假冒者。
目前最流行的”非对称加密”技术是 RSA,名字来自发明者: Rivest, Shamir, Adleman。当你访问一个安全的网站,比如银行官网,绿色锁图标代表 用了公钥密码学,验证服务器的密钥,然后建立临时密钥然后用对称加密保证通信安全。
第 34 集 机器学习 & 人工智能
计算机很擅长存放,整理,获取和处理大量数据,但如果想根据数据做决定呢?机器学习算法让计算机可以从数据中学习,然后自行做出预测和决定。大多数计算机科学家会说机器学习是为了实现人工智能这个更宏大目标的技术之一。机器学习和人工智能算法一般都很复杂,我们从简单例子开始:判断飞蛾是”月蛾”还是”帝蛾”,这叫”分类“。做分类的算法叫 “分类器“,很多算法会减少复杂性,把数据简化成 “特征“,”特征”是用来帮助”分类”的值,对于之前的飞蛾分类例子我们用两个特征:”翼展”和”重量”。
为了训练”分类器”做出好的预测,我们需要”训练数据“,为了得到数据我们派昆虫学家到森林里收集”月蛾”和”帝蛾”的数据,所以专家不只记录特征值,还会把种类也写上,这叫 “标记数据”。因为只有两个特征,很容易用散点图把数据视觉化,
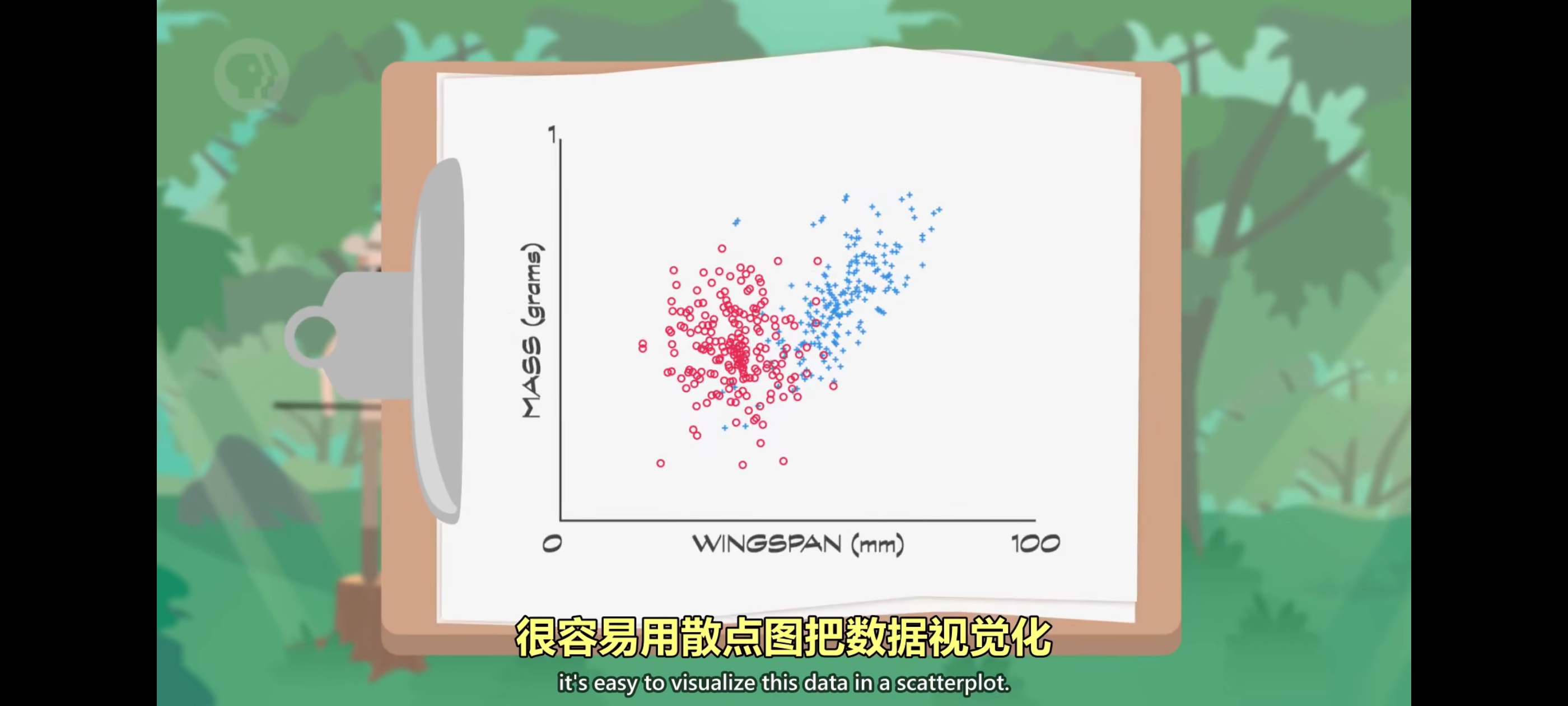
可以看到大致分成了两组但中间有一定重叠,想完全区分两个组比较困难,所以机器学习算法登场,这些线叫 “决策边界“。
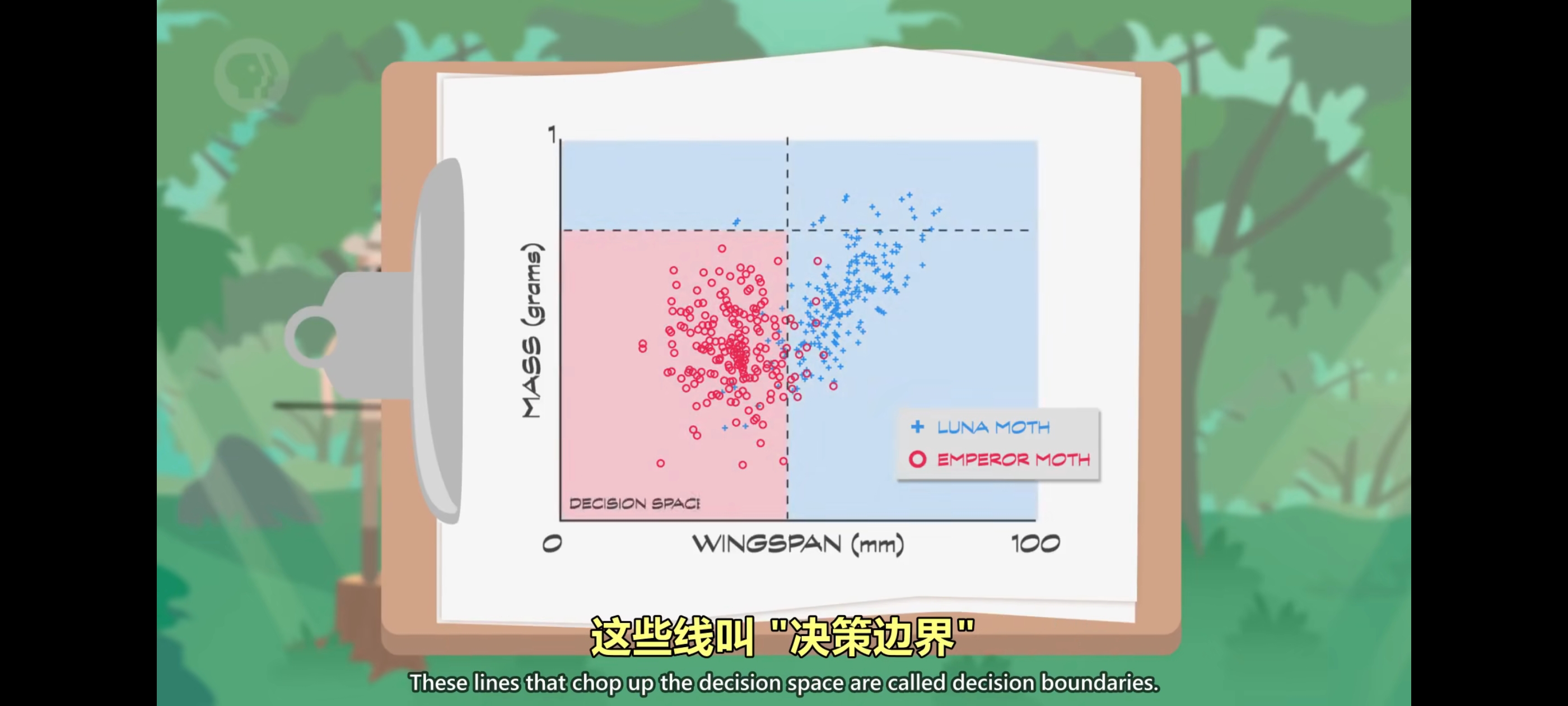
如果仔细看数据86只帝蛾在正确的区域但剩下14只在错误的区域,另一方面,82只月蛾在正确的区域,18个在错误的区域,这里有个表 记录正确数和错误数,这表叫”混淆矩阵“。
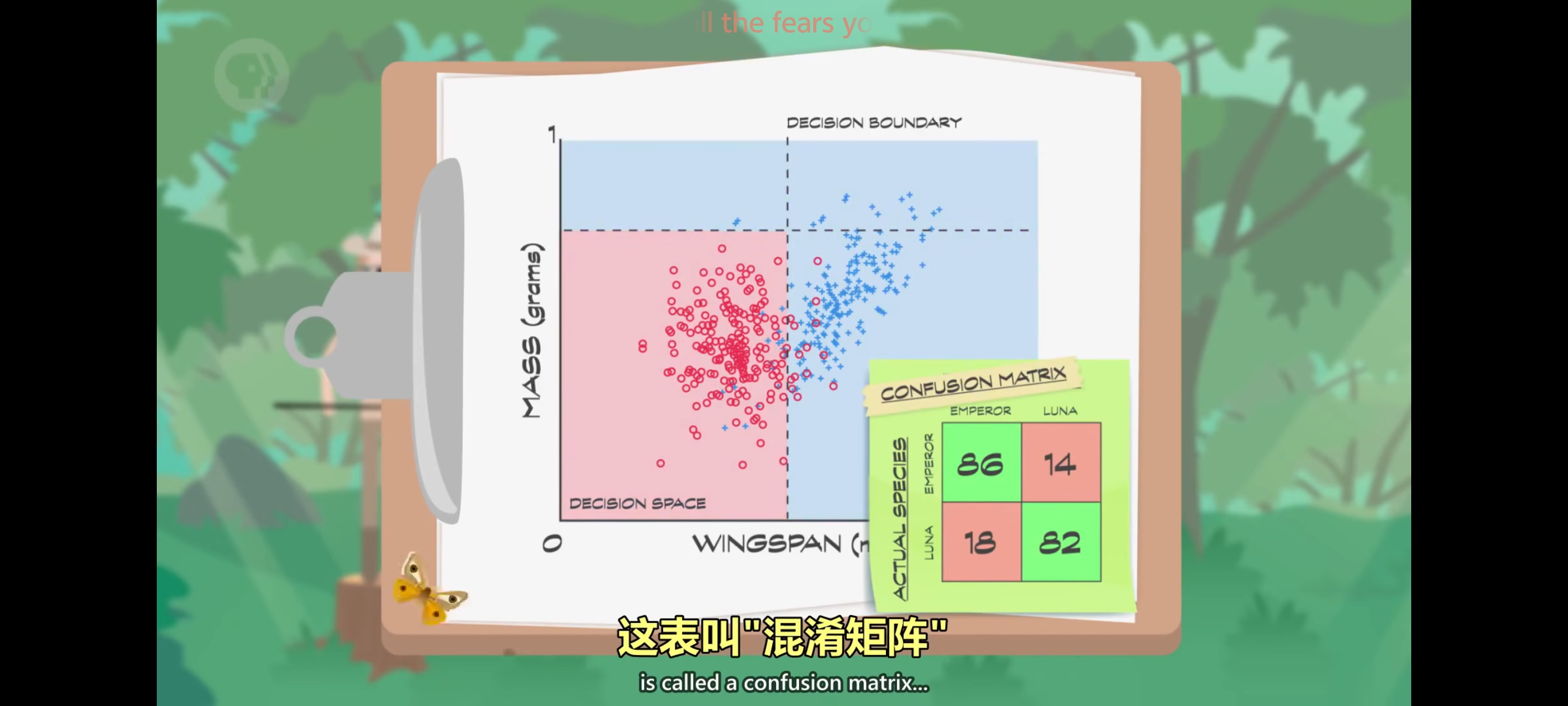
机器学习算法的目的是最大化正确分类 + 最小化错误分类,如果我们进入森林,碰到一只不认识的飞蛾,我们可以测量它的特征, 并绘制到决策空间上这叫 “未标签数据”。决策边界可以猜测飞蛾种类,这里我们预测是”月蛾”,这个把决策空间 切成几个盒子的简单方法,可以用”决策树“来表示,生成决策树的机器学习算法,需要选择用什么特征来分类,”决策树”只是机器学习的一个简单例子。

也有不用树的方法,比如”支持向量机“,本质上是用任意线段来切分”决策空间”。不一定是直线,可以是多项式或其他数学函数。

如果加第3个特征,比如”触角长度”,在三个维度上做决策边界,这些平面不必是直的,而且真正有用的分类器会有很多飞蛾种类。
有一大类机器学习算法用了统计学,但也有不用统计学的算法,其中最值得注意的是人工神经网络。回到飞蛾例子,看如何用神经网络分类,同样,这次也用重量和翼展,第一层输入层,另一边是输出层,有两个神经元:一个是帝蛾,一个是月蛾,中间有一个隐藏层负责把输入变成输出,负责干分类这个重活。神经元做的第一件事是把每个输入乘以一个权重,然后它会相加输入,对这个结果,用一个偏差值处理,做神经网络时,这些偏差和权重,一开始会设置成随机值,然后算法会调整这些值来训练神经网络,使用”标记数据”来训练和测试逐渐提高准确性。最后,神经元有激活函数,它也叫传递函数,会应用于输出,对结果执行最后一次数学修改,例如,把值限制在-1和+1之间或把负数改成0。这只是一个神经元,但加权,求和,偏置,激活函数会应用于一层里的每个神经元并向前传播,一次一层,隐藏层不是只能有一层,可以有很多层,”深度学习“因此得名。训练更复杂的网络 需要更多的计算量和数据,尽管神经网络50多年前就发明了,深层神经网络直到最近才成为可能,感谢强大的处理器和超快的GPU。
这些算法非常复杂,但还不够”聪明”,它们只能做一件事,分类飞蛾,找人脸,翻译,这种AI叫”弱AI“或”窄AI”,只能做特定任务但这不意味着它没用。真正通用的,像人一样聪明的AI,叫 “强AI“。学习什么管用,什么不管用,自己发现成功的策略,这叫 “强化学习“ 是一种很强大的方法。和人类的学习方式非常类似,人类不是天生就会走路,是上千小时的试错学会的。
第 35 集 计算机视觉
半个世纪来计算机科学家一直在想办法让计算机有视觉,因此诞生了”计算机视觉“这个领域,目标是让计算机理解图像和视频。
最简单的最合适拿来入门的计算机视觉算法是跟踪一个颜色物体,比如一个粉色的球,首先,我们记下球的颜色,保存最中心像素的 RGB 值,然后给程序喂入图像,让它找最接近这个颜色的像素。算法可以从左上角开始,逐个检查像素,计算和目标颜色的差异,检查了每个像素后,最贴近的像素,很可能就是球。我们可以在视频的每一帧图片跑这个算法跟踪球的位置。如果情况更极端一些比如比赛是在晚上,追踪效果可能会很差。如果球衣的颜色和球一样,算法就完全晕了,因此很少用这类颜色跟踪算法,除非环境可以严格控制。
为了简单,我们把图片转成灰度,放大其中一个杆子,看看边缘是怎样的。因为有垂直的颜色变化,我们可以说某像素是垂直边缘的可能性取决于左右两边像素的颜色差异程度,左右像素的区别越大,这个像素越可能是边缘。这个操作的数学符号看起来像这样
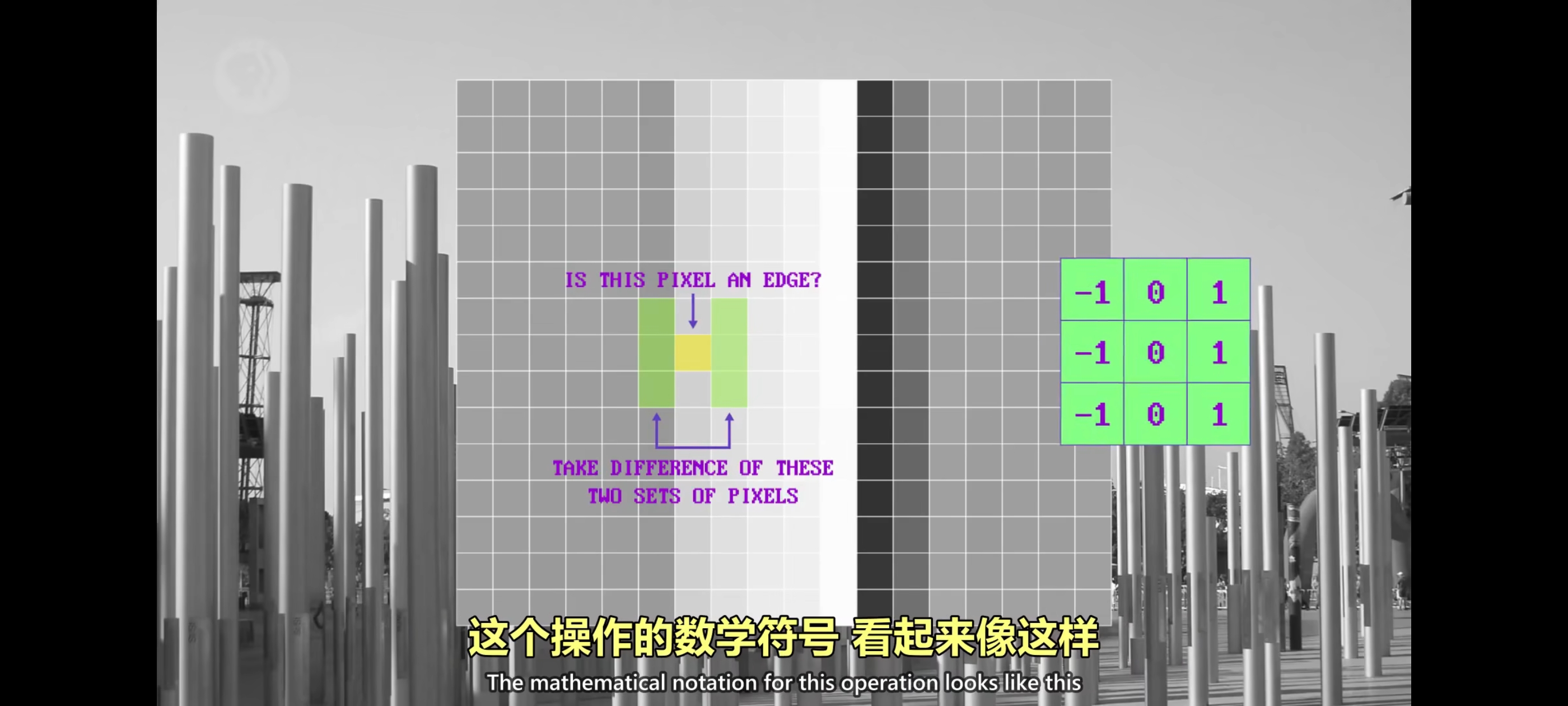
这叫”核“或”过滤器”,里面的数字用来做像素乘法,总和存到中心像素里。现在把”核”的中心,对准感兴趣的像素这指定了每个像素要乘的值,然后把所有数字加起来。把核应用于像素块,这种操作叫”卷积“。如果把”核”用于照片中每个像素,垂直边缘的像素值很高,水平边缘几乎看不见,如果要突出那些特征要用不同的”核”,用对水平边缘敏感的”核”,这两个边缘增强的核叫”Prewitt 算子“。这只是众多”核”的两个例子,”核”能做很多种图像转换,锐化图像,模糊图像,匹配特定形状,擅长找线段的”核“,擅长找线段的”核。
当计算机扫描图像时,最常见的是用一个窗口来扫,可以找出人脸的特征组合。虽然每个”核”单独找出脸的能力很弱,但组合在一起会相当准确,这是一个早期很有影响力的算法的基础叫 维奥拉·琼斯 人脸检测算法。如今的热门算法是 “卷积神经网络“。
神经网络的最基本单位是神经元,它有多个输入,然后会把每个输入乘一个权重值然后求总和。和预定义”核”不同,神经网络可以学习对自己有用的”核”来识别图像中的特征,”卷积神经网络“用一堆神经元处理图像数据,每个都会输出一个新图像,本质上是被不同的”核”处理了,输出会被后面一层神经元处理,卷积卷积再卷积,第一层可能会发现”边缘”这样的特征,下一层可以在这些基础上识别,然后下一层可以在”角落”上继续卷积,可能有识别简单物体的神经元比如嘴和眉毛,然后不断重复,逐渐增加复杂度,直到某一层把所有特征放到一起,眼睛,耳朵,嘴巴,鼻子。”卷积神经网络”不是非要很多很多层,但一般会有很多层,来识别复杂物体和场景,所以算是”深度学习“。
“维奥拉·琼斯”和”卷积神经网络”不只是认人脸,还可以识别手写文字,在 CT 扫描中发现肿瘤,监测马路是否拥堵。不管用什么算法,识别出脸之后,可以用更专用的计算机视觉算法来定位面部标志比如鼻尖和嘴角,有了标志点,判断眼睛有没有张开就很容易了。只是点之间的距离,也可以跟踪眉毛的位置,眉毛相对眼睛的位置可以代表惊喜或喜悦,根据嘴巴的标志点,检测出微笑也很简单,这些信息可以用”情感识别算法“来识别。
正如系列中常说的,抽象是构建复杂系统的关键
最近的技术发展,比如超快的GPU会开启越来越多可能性,视觉能力达到人类水平的计算机会彻底改变交互方式!
第 36 集 自然语言处理
人类语言叫”自然语言“,自然语言有大量词汇,有些词有多种含义,不同口音。人们在写作和说话时也会犯错,比如单词拼在一起发音,关键细节没说导致意思模糊两可。但大部分情况下,另一方能理解,因为人类有强大的语言能力,因此,让计算机拥有语音对话的能力,这个想法从构思计算机时就有了。”自然语言处理“因此诞生,简称 NLP,结合了计算机科学和语言学的一个跨学科领域。
NLP 早期的一个基本问题是怎么把句子切成一块块,了解单词类型有用,但不幸的是,很多词有多重含义,可以用作名词或动词,仅靠字典,不能解决这种模糊问题。开发了”短语结构规则“来代表语法规则,你可以给一门语言制定出一堆规则,用这些规则,可以做出”分析树“它给每个单词标了可能是什么词性,也标明了句子的结构,数据块更小更容易处理。处理, 分析, 生成文字是聊天机器人的最基本部件,早期聊天机器人大多用的是规则,专家把用户可能会说的话,和机器人应该回复什么,写成上百个规则。显然,这很难维护,而且对话不能太复杂。
如今大多用机器学习,用上GB的真人聊天数据来训练机器人,在 Facebook 的一个实验里,聊天机器人甚至发展出自己的语言,但实际上只是计算机在制定简单协议来帮助沟通。用机器学习从语言数据库中学习,如今准确度最高的语音识别系统用深度神经网络。was 中的 wah 和 sss,等等,这些构成单词的声音片段,叫“音素”。

使用快速傅里叶变换(FFT)

语音识别软件知道这些音素,英语有大概44种音素,所以本质上变成了音素识别还要把不同的词分开,弄清句子的开始和结束点,最后把语音转成文字。结合语言模型后,语音转文字的准确度会大大提高,里面有单词顺序的统计信息,比如:”她”后面很可能跟一个形容词,比如”很开心”,”她”后面很少是名词,如果不确定是 happy 还是 harpy,会选 happy,因为语言模型认为可能性更高。
第 37 集 机器人
机器人的定义有很多种,但总的来说,机器人由计算机控制,可以自动执行一系列动作的机器。robot (机器人) 一词首次出现在1920年的一部捷克戏剧,代表人造的类人角色,robot 源于斯拉夫语词汇 robota 代表强迫劳动。
第一台计算机控制的机器,出现在1940年代晚期,这些计算机数控的机器,简称 CNC 机器。可以执行一连串程序指定的操作,精细的控制让我们能生产之前很难做的物品,比如从一整块铝加工出复杂的螺旋桨。CNC 机器大大推进了制造业,不仅提高了制造能力和精确度还降低了生产成本。
对于简单运动比如机器爪子在轨道上来回移动,可以指示它移动到特定位置,它会一直朝那个方向移动,直到到达然后停下来。因为我们在不断缩小 当前位置和目标位置的距离,这个控制回路更准确的叫”负反馈回路“。负反馈回路有三个重要部分,首先是一个传感器,可以测量现实中的东西,根据传感器,计算和目标值相差多大得到一个”错误”,然后”控制器”会处理这个”错误”,决定怎么减小错误然后用泵,电机,加热元件,或其他物理组件来做出动作,在严格控制的环境中,这种简单控制回路也够用了。但在很多现实应用中,情况复杂得多,假设爪子很重,哪怕控制回路叫停了,惯性让爪子超过了预期位置,然后控制回路又开始运行叫爪子移动回去,一个糟糕的控制回路可能会让爪子不断来回移动。现实世界中机器人还会受到各种外力影响比如摩擦力,风,等等,为了处理这些外力,我们需要更复杂的控制逻辑,一个使用广泛的机制,有控制回路和反馈机制,叫 “比例-积分-微分控制器“,简称 “PID控制器“。
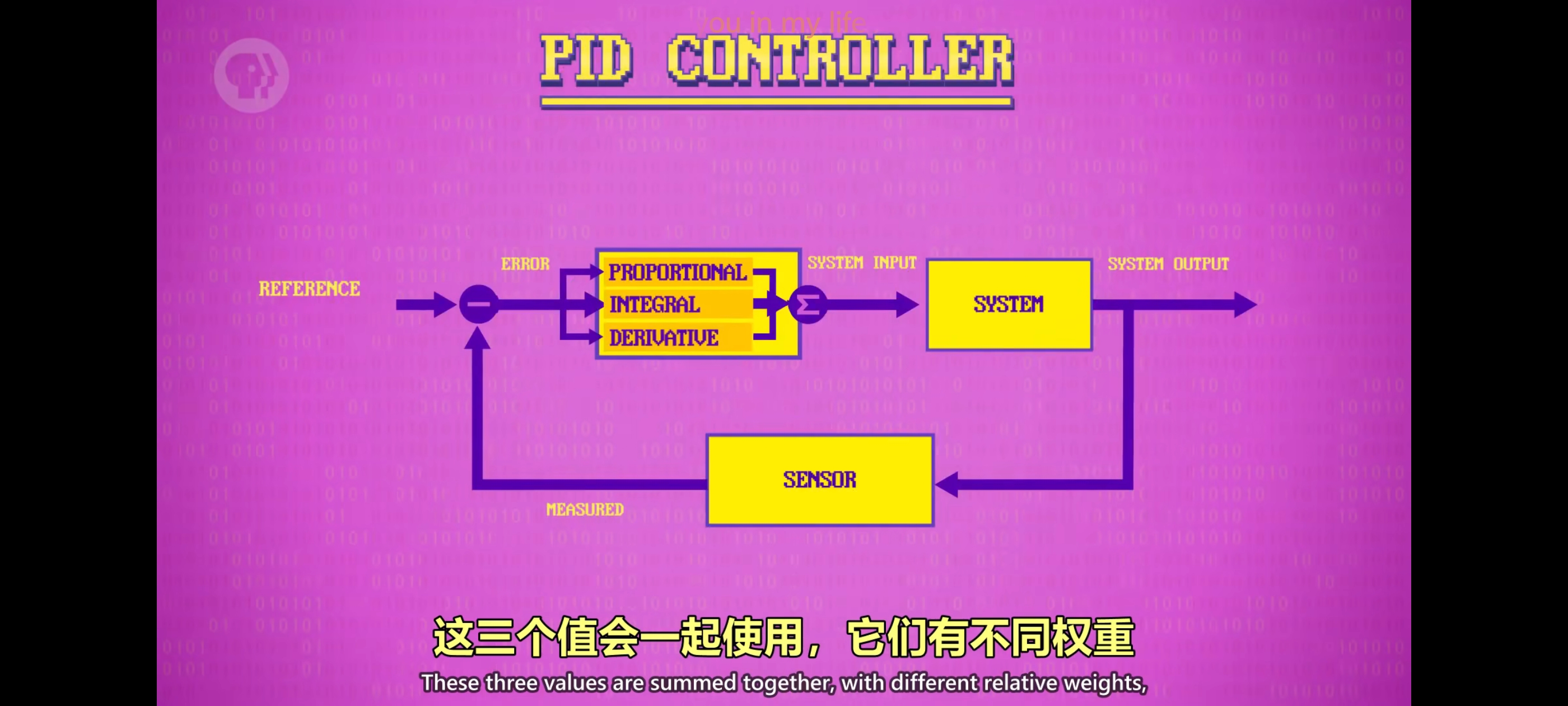
它以前是机械设备,现在全是纯软件了。这三个值会一起使用,它们有不同权重然后用来控制系统。
第 40 集 奇点,天网,计算机的未来
We’re in a golden age of computing and there’s so much going on, it’s impossible to summarize.
But most importantly, you can be a part of this amazing transformation and challenge,by learning about computing, and taking what’s arguably humanity’s greatest invention,to make the world a better place!