Crash Course Computer Science【计算机科学速成课】(3)
感谢速成课!感谢 Carrie Anne!感谢中文翻译组!~
原视频
Crash Course Computer Science
https://github.com/1c7/crash-course-computer-science-chinese
第 21 集 压缩
为了使文件能小一点,存大量文件,传输也快一些,人们使用压缩,把数据占用的空间压得更小,用更少的位(bit)来表示数据。
以吃豆人为例图像是4像素x4像素,每个像素3个字节,总共占48个字节(16x3=48),但我们可以压缩到少于 48 个字节。
一种方法是减少重复信息,最简单的方法叫游程编码(Run-Length Encoding)适合经常出现相同值的文件,比如吃豆人有7个连续黄色像素与其全存下来可以插入一个额外字节,代表有7个连续黄色像素然后删掉后面的重复数据。为了让计算机能分辨哪些字节是”长度” 哪些字节是”颜色”,格式要一致所以我们要给所有像素前面标上长度,有时候数据反而会变多。但是没有损失任何数据,我们可以轻易恢复到原来的数据。解压缩后,数据和压缩前完全一样,这叫”无损压缩“,没有丢失任何数据。

另一种无损压缩“字典编码”,它用更紧凑的方式表示数据块,我们使用一个字典,存储”代码”和”数据”间的对应关系。个字典,存储”代码”和”数据”间的对应关系。我们可以把图像看成一块块,而不是一个个像素。例如,把2个像素当成1块,为四对:白黄 黑黄 黄黄 白白,生成紧凑代码(compact codes)根据频率生成 “霍夫曼树“(Huffman Tree)来生成每组对应一个唯一编码的字典。
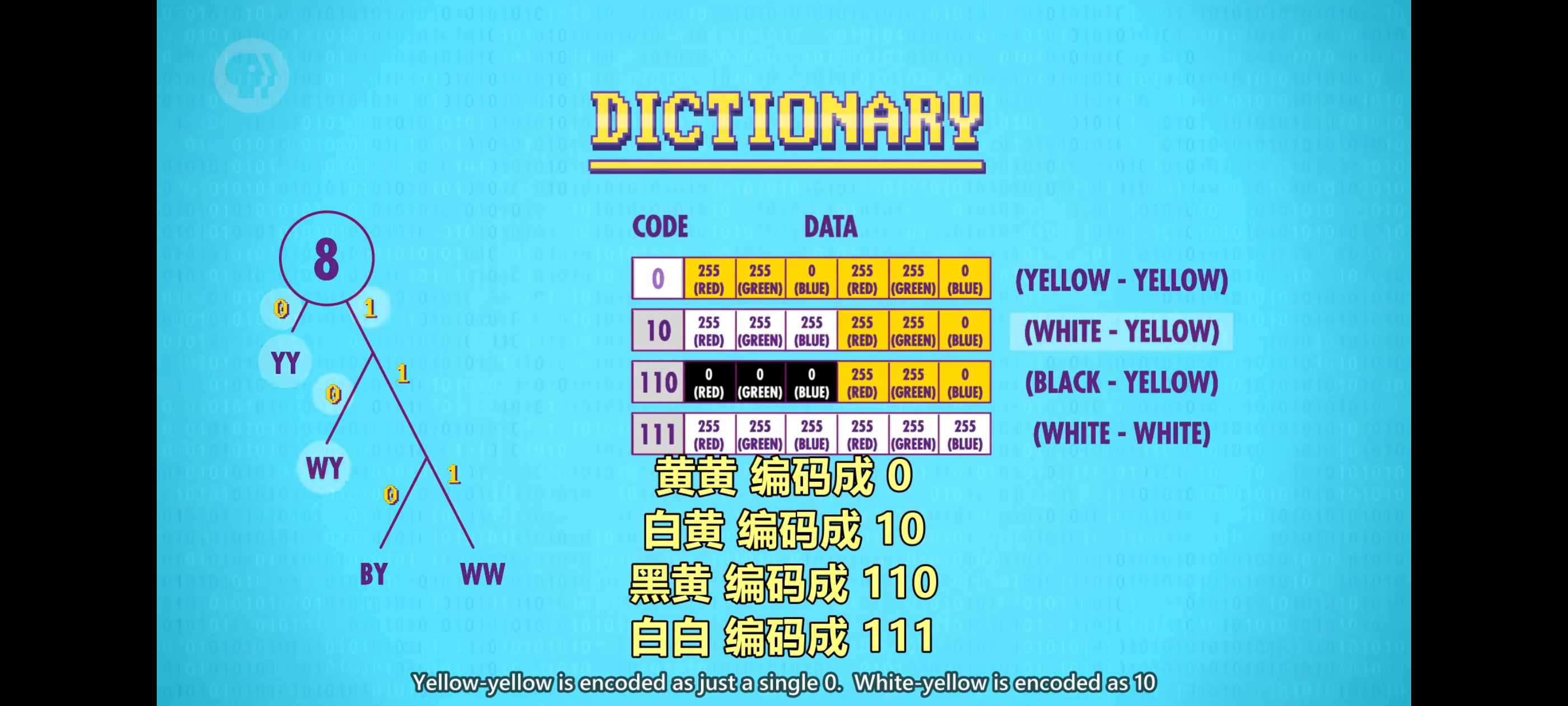
字典也要保存下来,否则这 14 bit的编码毫无意义。现在加上字典,图像是 30 个字节(bytes)。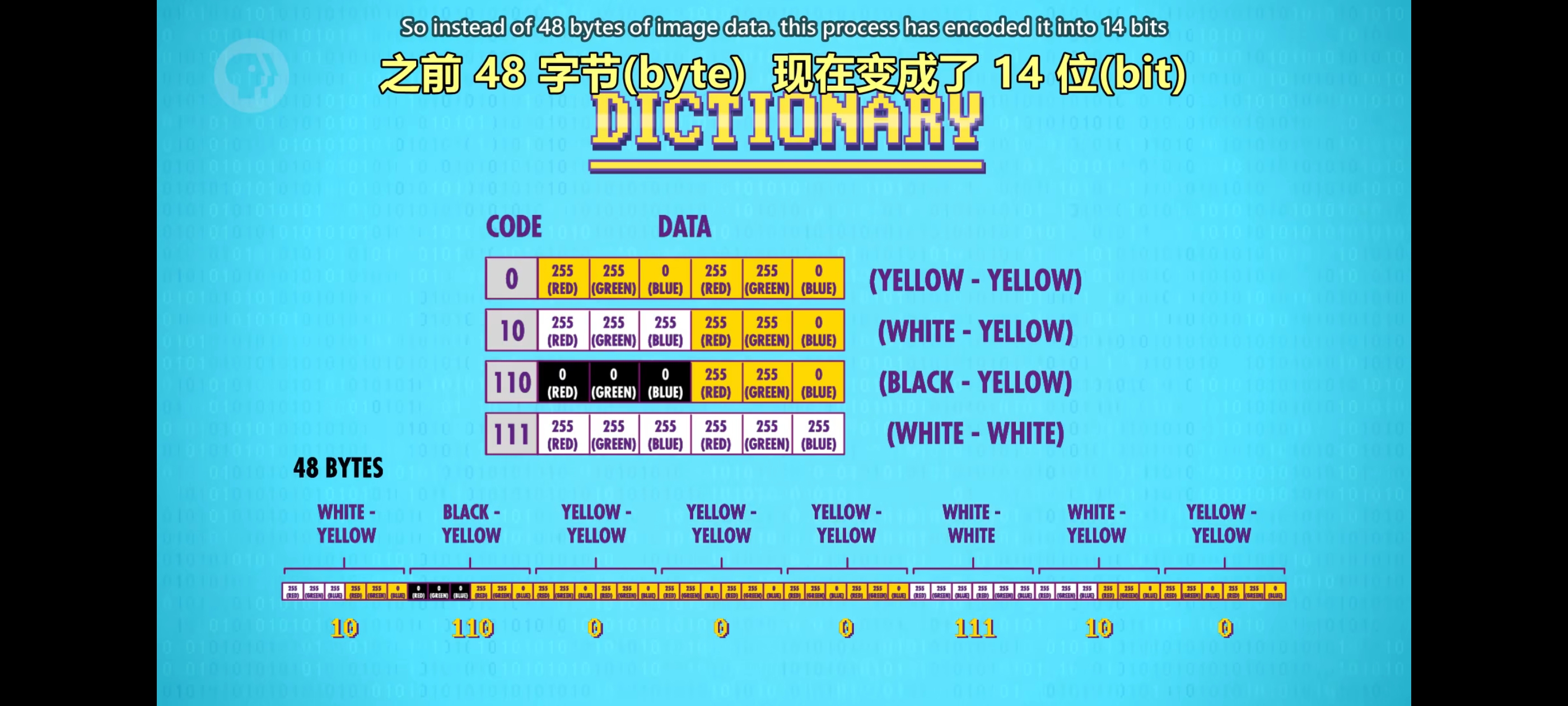
“消除冗余”和”用更紧凑的表示方法”,这两种方法通常会组合使用,几乎所有无损压缩格式都用了它们,比如 GIF, PNG, PDF, ZIP。但其他一些文件,丢掉一些数据没什么关系。我们可以丢掉那些人类看不出区别的数据,大多数有损压缩技术,都用到了这点。这种删掉人类无法感知的数据的方法,叫”感知编码“。
例如声音,用不同精度编码不同频段,听不出什么区别,不会明显影响体验。日常生活中你会经常碰到这类音频压缩所以你在电话里的声音和现实中不一样,压缩音频是为了让更多人能同时打电话,如果网速变慢了,压缩算法会删更多数据。和没压缩的音频格式相比,比如 WAV 或 FLAC,压缩音频文件如 MP3,能小10倍甚至更多。
感知编码依赖于人类的感知模型,模型来自”心理物理学”领域,是各种”有损压缩图像格式”的基础,最著名的是 JPEG,就像听力一样,人的视觉系统也不是完美的,我们善于看到尖锐对比,比如物体的边缘,但我们看不出颜色的细微变化。JPEG 利用了这一点,把图像分解成 8x8 像素块。然后删掉大量高频率空间数据,很多人眼看不出的小细节,可以删掉用一个简单的块来代替。

对所有 8x8 块做一样的操作,图片依然可以认出是什么,只是更粗糙一些。这个例子比较极端,进行了高度压缩,通常可以取得平衡,图片看起来差不多,但文件小不少。视频只是一长串连续图片,所以图片的很多方面也适用于视频,但视频可以做一些小技巧,因为帧和帧之间很多像素一样。比如背景,视频里不用每一帧都存这些像素,这叫时间冗余。我们可以利用了帧和帧之间的相似性,只存变了的部分,这比存所有像素更有效率。更高级的视频压缩格式会更进一步,找出帧和帧之间相似的补丁,然后用简单效果实现,比如移动和旋转,变亮和变暗。视频压缩器识别到相似性时,会用一个或多个补丁代表相似物体,然后帧之间直接移动这些补丁,所以你看到的不是实时的物体。
MPEG-4 是常见标准,可以比原文件小20倍到200倍,但用补丁的移动和旋转来更新画面,当压缩太严重时会出错,没有足够空间更新补丁内的像素。即使补丁是错的,视频播放器也会照样播放,导致一些怪异又搞笑的结果。

学习压缩非常重要,因为可以高效存储图片,音乐,视频,如果没有压缩看多人共享实时影像几乎不可能,因为你的带宽可能不够(会很卡),而且供应商不愿意免费传输那么多数据。
第 22 集 命令行界面
早期机械计算设备的人机交互使用齿轮,旋钮和开关等机械结构来输入输出,甚至早期电子计算机比如 Colossus 和 ENIAC,也是用一大堆机械面板和线来操作。输入一个程序可能要几星期,还没算上运行时间,运行完毕后想拿出数据,一般是打印到纸上。
到 1950 年代,机械输入完全消失,出现了打孔纸卡和磁带,但输出仍然是打印到纸上,还有大量指示灯,在运行中提供实时反馈,那个时代的特点是尽可能迁就机器,对人类好不好用是其次。例如打印纸带,为了方便计算机读取,纸带是连续的,纸孔可以方便地用机械或光学手段识别。而程序员则要花额外时间和精力转成计算机能理解的格式。
因为机器太贵了不能等人类慢慢敲命令和给数据,所以要同时放入程序和数据,这在 1950 年代晚期开始发生变化,一方面,小型计算机变得足够便宜,让人类来回和计算机交互变得可以接受,而另一方面大型计算机变得更快,能同时支持多个程序和多个用户。交互式操作时计算机需要某种方法来获得用户输入,人们借用了当时已经存在的数据录入机制:键盘。现代打字机是克里斯托弗·莱瑟姆·肖尔斯在 1868 年发明的,肖尔斯的打字机用了不寻常的布局,QWERTY,肖尔斯和他的团队设计了很多版才进化到这个布局。
过去一个世纪有不少新的键盘布局被发明,宣称各种好处,但人们已经熟悉了 QWERTY 布局根本不想学新布局,这是经济学家所说的转换成本,所以现在都快1个半世纪了我们还在用 QWERTY 键盘布局。当然,有很多变体,比如法国 AZERTY 布局,以及中欧常见的 QWERTZ 布局。
早期计算机用了一种特殊打字机,是专门用来发电报的,叫电传打字机,这些打字机是强化过的,可以用电报线发送和接收文本,按一个字母,信号会通过电报线,发到另一端,另一端的电传打字机会打出来,使得两人可以长距离沟通,基本是个蒸汽朋克版聊天室。
输入命令 ls,名字来自 list 的缩写,计算机会列出当前目录里的所有文件,unix 用 cat 命令显示文件内容,cat 是连接(concatenate)的缩写,然后指定文件名,指定的方法是写在 cat 命令后面,传给命令的值叫 参数。如果同一个网络里有其他人,可以用 finger 命令找朋友。
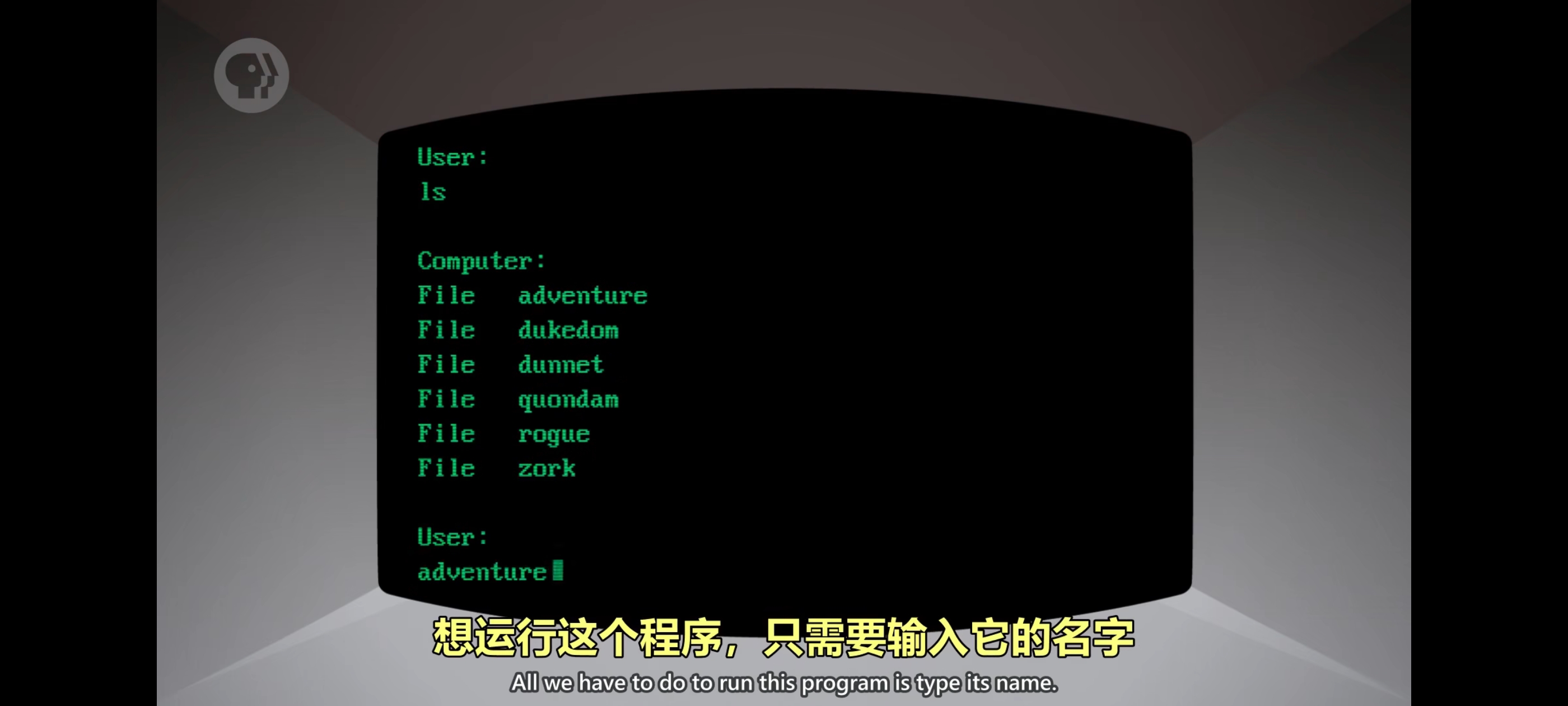
电传打字机直到1970年代左右都是主流交互方式,尽管屏幕最早出现在 1950 年代但对日常使用太贵而且分辨率低。然而因为针对普通消费者的电视机开始量产同时处理器与内存也在发展,到1970年代,屏幕代替电传打字机变得可行。与其为屏幕专门做全新的标准,工程师直接用现有的电传打字机协议,屏幕就像无限长度的纸,除了输入和输出字,没有其它东西,协议是一样的,所以计算机分不出是纸还是屏幕,这些”虚拟电传打字机”或”玻璃电传打字机”叫终端。到 1970 年代末屏幕成了标配,命令行界面太原始了,但即便只有文字程序员也找到了一些方法,让它变得有趣一些。
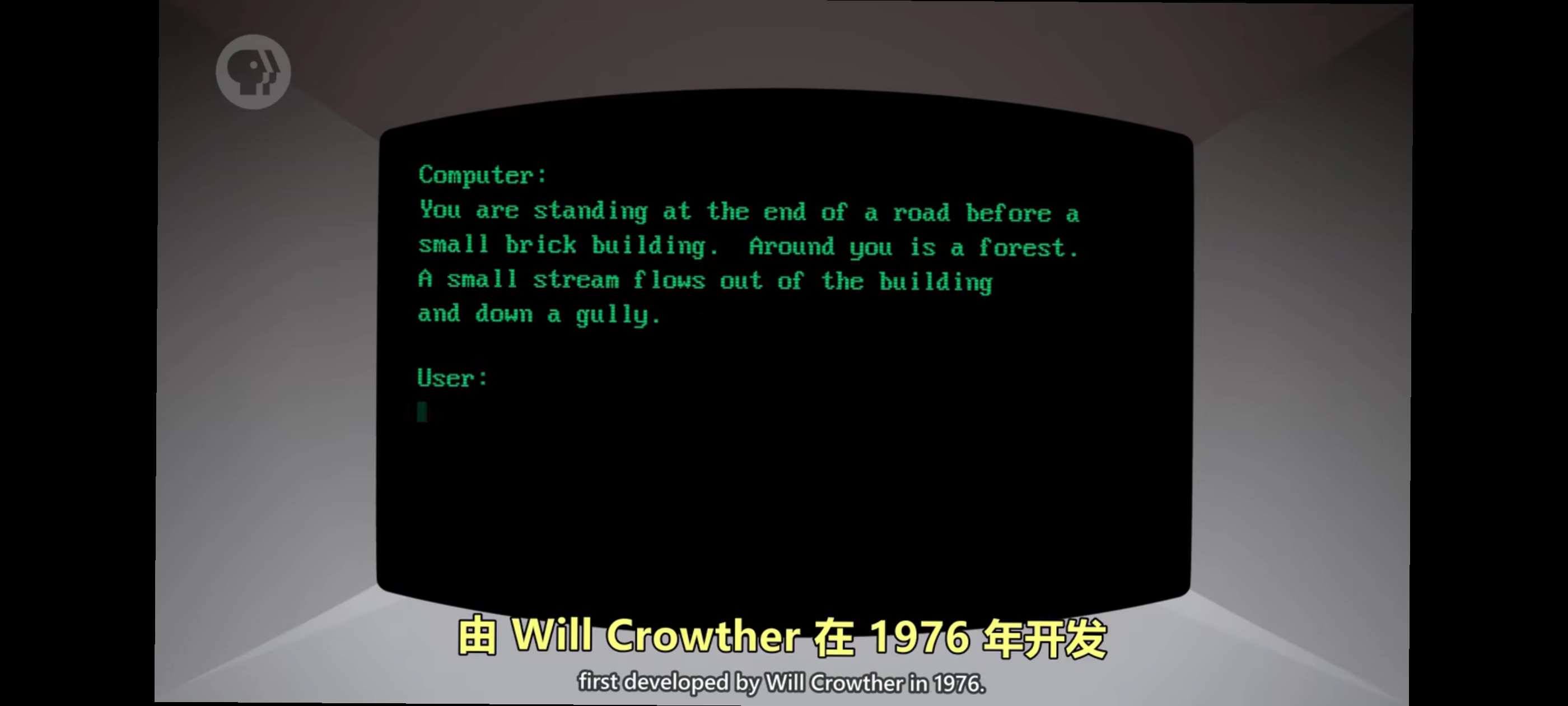
例如早期的著名交互式文字游戏 Zork,出现于 1977 年早期游戏玩家需要丰富的想象力,想像自己身在虚构世界,比如”四周漆黑一片附近可能有怪物会吃掉你”。由 Will Crowther 在 1976 年开发,游戏中,玩家可以输入1个词或2个词的命令来移动人物,和其他东西交互,捡物品等,然后游戏会像旁白一样,输出你的当前位置,告诉你能做什么动作,以及你的动作造成的结果。
原始版本只有 66 个地方可供探索,但它被广泛认为是最早的互动式小说。游戏后来从纯文字进化成多人游戏简称 MUD,或多人地牢游戏,是如今 MMORPG 的前辈(大型多人在线角色扮演游戏)。命令行界面虽然简单但十分强大,编程大部分依然是打字活所以用命令行比较自然,即使是现在大多数程序员工作中依然用命令行界面。而且用命令行访问远程计算机是最常见的方式,比如服务器在另一个国家,我们可以在 Windows 搜索栏中输入 cmd或在 Mac 上搜 Terminal,然后就可以装 Zork 玩!
第 23 集 屏幕 & 2D图形显示
早期的屏幕无法显示清晰的文字,而打印到纸上有更高的对比度和分辨率,早期屏幕的典型用途是跟踪程序的运行情况,比如寄存器的值。到1960年代,人们开始用屏幕做很多酷炫的事情,几十年间出现了很多显示技术,但最早最有影响力的是阴极射线管(CRT),原理是把电子发射到有磷光体涂层的屏幕上。当电子撞击涂层时会发光几分之一秒,由于电子是带电粒子,路径可以用磁场控制,屏幕内用板子或线圈把电子引导到想要的位置,既然可以这样控制,有 2 种方法绘制图形:
引导电子束描绘出形状,这叫”矢量扫描“,因为发光只持续一小会儿,如果重复得足够快可以得到清晰的图像。
按固定路径,一行行来从上向下,从左到右,不断重复,只在特定的点打开电子束,以此绘制图形,这叫 “光栅扫描“,用这种方法,可以用很多小线段绘制形状甚至文字。
因为显示技术的发展,我们终于可以在屏幕上显示清晰的点,叫”像素”,液晶显示器,简称 LCD,和以前的技术相当不同,但 LCD 也用光栅扫描,每秒更新多次像素里红绿蓝的颜色。
因为像素占太多内存,很多早期计算机不用像素,计算机科学家和工程师,得想一些技巧来渲染图形等内存发展到足够用。早期计算机不存大量像素值 而是存符号,80x25个符号最典型,如果每个字符用 8 位表示,比如用 ASCII,总共才 16000 位,这种大小更合理,为此,计算机需要额外硬件,来从内存读取字符,转换成光栅图形,这样才能显示到屏幕上。这个硬件叫 “字符生成器“,基本算是第一代显卡,它内部有一小块只读存储器,简称 ROM。存着每个字符的图形,叫”点阵图案”,如果图形卡看到一个 8 位二进制,发现是字母 K,那么会把字母 K 的点阵图案光栅扫描显示到屏幕的适当位置。为了显示,”字符生成器” 会访问内存中一块特殊区域这块区域专为图形保留,叫 屏幕缓冲区。程序想显示文字时,修改这块区域里的值就行。字符集实在太小,做不了什么复杂的事,因此对 ASCII 进行了各种扩展,加新字符。
字符生成器是一种省内存的技巧,但没办法绘制任意形状,绘制任意形状很重要,因为电路设计,建筑平面图,地图,好多东西都不是文字。为了绘制任意形状,同时不吃掉所有内存,计算机科学家用 CRT 上的”矢量模式”,概念非常简单:所有东西都由线组成。如果要显示文字,就用线条画出来。
1962 年是一个大里程碑 Sketchpad 诞生,一个交互式图形界面,用途是计算机辅助设计 (CAD),它被广泛认为是第一个完整的图形程序,发明人 伊万·萨瑟兰 后来因此获得图灵奖。为了与图形界面交互 Sketchpad 用了当时发明不久的输入设备 光笔。一个有线连着电脑的触控笔,笔尖用光线传感器,可以检测到显示器刷新,笔尖用光线传感器,可以检测到显示器刷新,通过判断刷新时间,电脑可以知道笔的位置,有了光笔和各种按钮 用户可以画线和其他简单形状。Sketchpad 可以让线条完美平行,长度相同,完美垂直90度,甚至动态缩放。用户还可以保存设计结果,方便以后再次使用,甚至和其他人分享。你可以有一整个库,里面有电子元件和家具之类的,可以直接拖进来用。Sketchpad 和光笔让人大开眼界,它们代表了人机交互方式的关键转折点。
最早用真正像素的计算机和显示器出现于 1960 年代末,内存中的位(Bit) 对应屏幕上的像素,这叫 位图显示。现在我们可以把图形想成一个巨大像素值矩阵,绘制任意图形了。计算机把像素数据存在内存中一个特殊区域叫”帧缓冲区“,早期时,这些数据存在内存里后来存在高速视频内存里,简称 VRAM。VRAM 在显卡上,这样访问更快如今就是这样做的。程序可以操纵”帧缓冲区”中的像素数据,实现交互式图形。程序员不会浪费时间从零写绘图函数而是用预先写好的函数来做,画直线,曲线,图形,文字等。
第 25 集 个人计算机革命
“第一台个人计算机”这个名号,有很多竞争者,不过第一台取得商业成功的个人计算机争议较小:Altair 8800,首次亮相在 1975 年《Popular Electronics》封面,售价 $439 美元,需要自己组装。但程序还是要用 机器码写,写起来很麻烦,即使计算机爱好者也讨厌写,年轻的比尔·盖茨和保罗·艾伦他们当时是19岁和22岁,联系了制造 Altair 8800 的 MITS 公司,建议说,如果能运行 BASIC 程序会对爱好者更有吸引力。BASIC 是一门更受欢迎更简单的编程语言,为此,他们需要一个程序把 BASIC 代码转成可执行机器码,这叫 解释器 (interpreter)。”解释器”和”编译器”类似,区别是”解释器”运行时转换而”编译器”提前转换。
MITS 表示感兴趣,同意与 Bill 和 Paul 见个面,让他们演示一下,问题是,他们还没写好解释器,所以他们花了几个星期赶工,最后在飞机上完成了代码。他们在墨西哥阿尔伯克基(城市)的 MITS 总部做演示时,才知道代码可以成功运行,幸运的是进展顺利 MITS 同意在计算机上搭载他们的软件,Altair BASIC 成了微软的第一个产品。
Altair 8800 大量催生了更多计算机爱好者,最具传奇色彩的小组是”家酿计算机俱乐部”,第一次小组聚会在1975年3月24岁的 Steve Wozniak 被 Altair 8800 大大激励,开始想设计自己的计算机。1976年5月,他向小组展示了原型机,他的设计不同寻常要连到电视显示,并提供文本界面,同是俱乐部成员和大学朋友的 史蒂夫·乔布斯,建议说与其免费分享设计,不如直接出售装好的主板,但用户依然需要自己加键盘,电源和机箱,1976年7月开始发售,价格$666.66美元,它叫 Apple-I ,苹果计算机公司的第一个产品。
1977 年市场上有了三款开箱即用的计算机,第一款是 Apple-II,苹果公司第一个提供全套设备的产品,设计和制造工艺都是专业的,它还提供了简单彩色图形和声音输出,这些功能对低成本机器非常了不起,Apple-II 卖了上百万套,把苹果公司推到了个人计算机行业的前沿。第二款是”TRS-80 1型”,由 Tandy 公司生产,由 Radioshack 销售,所以叫 TRS。虽然不如 Apple-II 先进但因为价格只有一半,所以卖得很火爆。最后一款是 Commodore PET 2001,有一体化设计,集成了计算机,显示器,键盘和磁带驱动器,目标是吸引普通消费者,计算机和家用电器之间的界限开始变得模糊。它们都自带了 BASIC 解释器,让不那么精通计算机的人也能用 BASIC 写程序。
这引起了全球最大计算机公司 IBM 的注意,其市场份额从1970年的60% 在1980年降到了30%左右,因为IBM忽略了增长的”微型计算机”市场。随着微型计算机演变成个人计算机,IBM 知道他们需要采取行动。经过短短一年,IBM 个人计算机发布了,简称 IBM PC,产品立马取得了成功,长期信任 IBM 品牌的企业买了很多,但最有影响力的是它使用 “开放式架构“,有良好的文档和扩展槽使得第三方可以做硬件/外设,包括显卡,声卡,外置硬盘,游戏控制杆以及无数其它组件,这刺激了创新,激发了竞争,产生了巨大的生态系统。那些生产非”IBM兼容”计算机的公司 (一般性能更好)都失败了,只有苹果公司在没有”IBM兼容“的情况下保持了足够市场份额。苹果公司最终选了相反的方式:”封闭架构“,即自己设计一切,用户一般无法加新硬件到计算机中,意味着苹果公司要做自己的计算机,自己的操作系统,还有自己的外围设备,如显示器,键盘和打印机,通过控制整个范围,从硬件到软件,苹果能控制用户体验并提高可靠性。
为了在低成本个人计算机的竞争冲击下生存下来,苹果需要提高自身水平 提供比 PC 和 DOS 更好的用户体验,他们的答案是 Macintosh,于 1984 年发布,一台突破性价格适中的一体式计算机用的不是命令行界面,而是图形界面,还带一个鼠标。
第 26 集 图形用户界面
人们认为是 Macintosh 把图形用户界面(GUI)Graphical User Interfaces 变成主流,但实际上图形界面是数十年研究的成果。现代图形界面的先驱可以说是 道格拉斯·恩格尔巴特。
二战期间恩格尔巴特驻扎在菲律宾做雷达操作员,他读了万尼瓦尔·布什的 Memex 文章,这些文章启发了他。当他海军服役结束时,他回到学校 1955年在 UCB 取得博士学位,他沉溺于新兴的计算机领域。他在1962年一份开创性报告中汇集了各种想法,报告名为:”增强人类智力“。恩格尔巴特认为,人类面临的问题比解决问题的能力增长得更快,因此,找到增强智力的方法似乎是必要且值得一做的目标。他构想计算机不仅做自动化工作,也可以成为未来知识型员工应对复杂问题的工具。伊凡·苏泽兰 的”几何画板”进一步启发了恩格尔巴特,他决定动手把愿景变为现实开始招募团队来做 oN-Line System。他意识到如果只有键盘对他想搭建的程序来说是不够的,1964年,和同事比尔·英格利希的共同努力下,他创造了第一个计算机鼠标,尾部有一根线,看起来很像老鼠。
1968年 恩格尔巴特在”秋季计算机联合会议”展示了他的系统,这次演示 被视为如今所有演示(demo)的祖先,演示有90分钟展现了现代计算机的许多功能:包括位图图像,视频会议,文字处理,和实时协作编辑文件。还有现代图形界面的原型比如鼠标和多窗口,不过窗口不能重叠。就像其它”跨时代”的产品一样,它最终失败了,但它对当时的计算机研究者影响巨大,恩格尔巴特因此获得1997年图灵奖。
为了让计算机易于使用,需要的不只是花哨的图形,还要借助一些人们已经熟悉的概念。让人们不用培训就能很快明白如何使用,施乐的答案是将2D屏幕当作”桌面“,就像桌面上放很多文件一样,用户可以打开多个程序,每个程序都在一个框里,叫”窗口”。

就像桌上的文件一样,窗口可以重叠,挡住后面的东西,还有桌面配件,比如计算器和时钟。用户可以把配件在屏幕上四处移动,它不是现实桌面的完美复制,而是用桌面这种隐喻,因此叫”桌面隐喻“。有很多方法来设计界面但 Alto 团队用窗口,图标,菜单和指针来做,因此叫 WIMP 界面。如今大部分图形界面都用这个,它还提供了一套基本部件,可复用的基本元素比如按钮,打勾框,滑动条和标签页,GUI 程序就是这些小组件组成的。
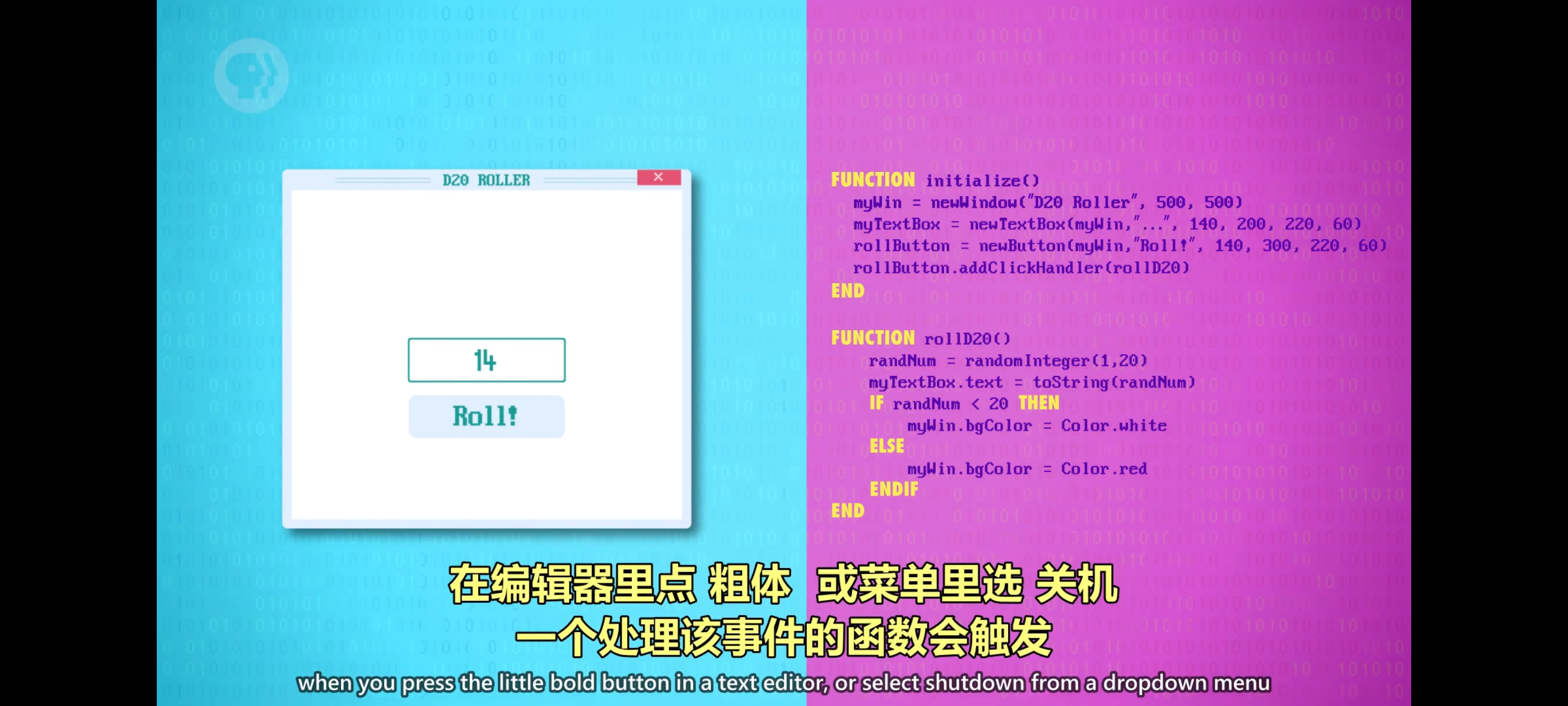
试着写一个简单例子,首先,我们必须告诉操作系统为程序创建一个窗口,通过 GUI API 实现需要指定窗口的名字和大小,假设是 500×500 像素,现在再加一些小组件,一个文本框和一个按钮。创建它们需要一些参数,首先要指定出现在哪个窗口因为程序可以有多个窗口,还要指定默认文字窗口中的 X,Y 位置以及宽度和高度。现在我们有个看起来像 GUI 程序的东西但如果点 Roll 按钮,什么也不会发生,在之前的例子中,代码是从上到下执行的,但 GUI 是 “事件驱动编程“,代码可以在任意时间执行以响应事件。这里是用户触发事件 比如点击按钮,选一个菜单项,或滚动窗口。假设当用户点 Roll 按钮,产生1到20之间的随机数,然后在文本框中,显示这个数字,我们可以写一个函数来做到这些,最后,把代码与”事件”相连每次点按钮时都触发代码。
施乐卖的是印刷机但在文本和图形制作工具领域也有领先,例如,他们首先使用了”剪切“”复制“”粘贴“这样的术语。这个比喻来自编辑打字机文件,真的是剪刀”剪切”然后胶水”粘贴” 到另一个文件。苹果第一款有图形界面和鼠标的产品,是 1983 年发行的 Apple Lisa,虽然比施乐之星便宜不少但在市场上同样失败。苹果的另一个项目Macintosh,于 1984 年发布,它成功了,开售100天就卖了7万台。一个大问题是:没人给这台新机器做软件,之后情况变得更糟,竞争对手赶上来了。随着苹果的财务状况日益严峻以及和苹果新 CEO 约翰·斯卡利的关系日益紧张,史蒂夫乔布斯被赶出了苹果公司。几个月后,微软发布了 Windows 1.0,它也许不如 Mac OS 漂亮,但让微软在市场中站稳脚跟奠定了统治地位。十年内,95%的个人计算机上都有微软的 Windows。Windows 早期版本都是基于 DOS 而 DOS 设计时没想过运行图形界面,但 Windows 3.1 之后微软开始开发新的,面向消费者的 GUI 操作系统叫 Windows 95。这是一个意义非凡的版本不仅提供精美的界面,还有 Mac OS 没有的高级功能,比如”多任务“和”受保护内存“,Windows 95 引入了许多如今依然见得到的 GUI 元素,比如开始菜单,任务栏和 Windows 文件管理器。
今天无论你用的是Windows,Mac,Linux 或其他 GUI,几乎都是施乐奥托 WIMP 的变化版。
第 27 集 3D 图形
在3D图像中, 点的坐标不再是两点, 而是三点, X,Y,Z,但2D的电脑屏幕上不可能有 XYZ 立体坐标轴,所以有图形算法负责把3D坐标”拍平”显示到2D屏幕上,这叫”3D投影“。所有的点都从3D转成2D后,就可以用画2D线段的函数来连接这些点,这叫 “线框渲染“。在3D图形学中我们叫三角形”多边形”(Polygons),一堆多边形的集合叫 网格,网格越密,表面越光滑,细节越多,但意味着更多计算量,游戏设计者要平衡角色的真实度和多边形数量。因此有算法用来简化网格,之所以三角形更常用而不是用正方形,或其它更复杂的图形,是因为三角形的简单性,如果给3个3D点,我能画出一个平面,而且只有这一个答案。
3D图像需要填充,填充图形的经典算法叫 扫描线渲染 (Scanline Rendering)于1967年诞生在犹他州大学,扫描线算法先读多边形的3个点,找最大和最小的Y值,只在这两点间工作,然后算法从上往下,一次处理一行,计算每一行和多边形相交的2个点,因为是三角形,如果相交一条边, 必然相交另一条。扫描线算法会填满2个相交点之间的像素。填充的速度叫 fillrate(填充速率),这样的三角形比较丑,边缘满是锯齿,一种减轻锯齿的方法叫抗锯齿(Antialiasing)。与其每个像素都涂成一样的颜色,可以判断多边形切过像素的程度,来调整颜色,如果像素在多边形内部,就直接涂颜色,如果多边形划过像素,颜色就浅一些,这种边缘羽化的效果看着更舒服些,抗锯齿被广泛使用,比如字体和图标。
在3D场景中,多边形到处都是,但只有一部分能看见因为其它的被挡住了这叫遮挡。最直接的处理办法是用排序算法,从远到近排列,然后从远到近渲染,这叫 画家算法 因为画家也是先画背景,然后再画更近的东西。还有一种方法叫 深度缓冲,因为这个算法不用排序,所以速度更快,简而言之,Z-buffering 算法会记录场景中每个像素和摄像机的距离,在内存里存一个数字矩阵,每个像素的距离被初始化为”无限大”,然后 Z-buffering 从列表里第一个多边形开始处理,也就是A,它和扫描线算法逻辑相同,但不是给像素填充颜色,而是把多边形的距离和 Z-Buffer 里的距离进行对比,它总是记录更低的值。
3D游戏中有个优化叫 背面剔除,三角形有两面,正面和背面,游戏角色的头部或地面,只能看到朝外的一面,所以为了节省处理时间,会忽略多边形背面,减了一半多边形面数,但有个bug是如果进入模型内部往外看头部和地面会消失。3D场景中, 物体表面应该有明暗变化,为了举例,我们从茶壶上挑3个不同位置的多边形,这次要考虑这些多边形面对的方向,它们不平行于屏幕,而是面对不同方向,他们面对的方向叫 “表面法线“,我们可以用一个垂直于表面的小箭头来显示这个方向,现在加个光源,每个多边形被照亮的程度不同有的更亮,因为面对的角度导致更多光线反射到观察者。
举个例子,底部的多边形向下倾斜,远离光源,所以更暗一些,类似的,最右的多边形更背对光源所以只有部分照亮,最后是左上角的多边形,因为它面对的角度意味着会把光线反射到我们这里,所以会显得更亮。这叫 平面着色,是最基本的照明算法。
为了使多边形的边界不明显,看起来更光滑,因此开发了更多算法比如 高洛德着色 和 冯氏着色,不只用一种颜色给整个多边形上色而是以巧妙的方式改变颜色,得到更好的效果。再大的场景,过程都是一样的一遍又一遍,处理所有多边形,扫描线填充, 抗锯齿, 光照, 纹理化。为了加速渲染,我们可以把3D场景分解成多个小部分,然后并行渲染,而不是按顺序渲染。CPU不是为此设计的,因此图形运算不快,所以,计算机工程师为图形做了专门的处理器,叫 GPU “图形处理单元“。GPU 在显卡上,周围有专用的 RAM,所有网格和纹理都在里面,让 GPU 的多个核心可以高速访问,现代显卡,如 GeForce GTX 1080 TI,有3584个处理核心,提供大规模并行处理,每秒处理上亿个多边形!
第 28 集 计算机网络
我们可能觉得计算机和网络密切相关,但事实上,1970年以前大多数计算机是独立运行的。然而因为大型计算机开始随处可见,分享数据和资源渐渐变得有用起来,首个计算机网络出现了。第一个计算机网络出现在1950~1960年代,通常在公司或研究室内部使用,为了方便信息交换,比把纸卡或磁带送到另一栋楼里更快速可靠,这叫”球鞋网络“。第二个好处是能共享物理资源,举个例子,与其每台电脑配一台打印机可以共享一台联网的打印机,早期网络也会共享存储空间,因为每台电脑都配存储器太贵了。
计算机近距离构成的小型网络叫局域网,简称LAN。局域网能小到是同一个房间里的两台机器,或大到校园里的上千台机器。尽管开发和部署了很多不同 LAN 技术,其中最著名和成功的是”以太网“, 开发于1970年代在施乐的”帕洛阿尔托研究中心”诞生, 今日仍被广泛使用。以太网的最简单形式是:一条以太网电线连接数台计算机,当一台计算机要传数据给另一台计算机时,它以电信号形式,将数据传入电缆,以太网需要每台计算机有唯一的 媒体访问控制地址简称 MAC地址,这个唯一的地址放在头部,作为数据的前缀发送到网络中。所以,计算机只需要监听以太网电缆,只有看到自己的 MAC 地址,才处理数据。现在制造的每台计算机都自带唯一的MAC地址,用于以太网和无线网络。
多台电脑共享一个传输媒介,这种方法叫 “载波侦听多路访问“ 简称”CSMA”。以太网的”载体”是铜线 WiFi 的”载体”是传播无线电波的空气。很多计算机同时侦听载体,所以叫”侦听”和”多路访问”,而载体传输数据的速度 叫”带宽“。随着网络流量上升两台计算机想同时写入数据的概率也会上升,这叫冲突数据全都乱套了。计算机能够通过监听电线中的信号检测这些冲突,最明显的解决办法是停止传输,等待网络空闲,然后再试一遍,但其他等着的计算机可能在任何停顿间隙闯入,导致越来越多冲突。以太网有个超简单有效的解决方法,当计算机检测到冲突 就会在重传之前等待一小段时间,跟之前一样如果所有计算机用同样的等待时间是不行的,所以加入一个随机时间。但不能完全解决问题,所以要用另一个小技巧。
如果再次发生冲突表明有网络拥塞,这次不等1秒,而是等2秒,如果再次发生冲突 等4秒 然后8秒 16秒等等直到成功传输。因为计算机的退避,冲突次数降低了,数据再次开始流动起来,网络变得顺畅。这种指数级增长等待时间的方法叫:指数退避。以太网和WiFi都用这种方法,很多其他传输协议也用。
为了减少冲突+提升效率,我们需要减少同一载体中设备的数量,载体和其中的设备总称 “冲突域”。为了减少冲突,我们可以用交换机把它拆成两个冲突域,交换机位于两个更小的网络之间,必要时才在两个网络间传数据。交换机会记录一个列表写着哪个 MAC 地址在哪边网络,如果F想发数据给A 数据会通过交换机,两个网络都会被短暂占用,大的计算机网络也是这样构建的,包括最大的网络 - 互联网,也是多个连在一起的稍小一点网络使不同网络间可以传递信息。这些大型网络有趣之处是从一个地点到另一个地点通常有多条路线,这就带出了另一个话题 路由。连接两台相隔遥远的计算机或网路,最简单的办法是分配一条专用的通信线路,早期电话系统就是这样运作的。传输数据的另一个方法是 “报文交换“,不像之前A和B有一条专有线路,消息会经过好几个站点,报文交换的好处是可以用不同路由使通信更可靠更能容错。消息沿着路由跳转的次数叫”跳数“(hop count),记录跳数很有用,因为可以分辨出路由问题。
举例,假设芝加哥认为去米苏拉的最快路线是奥马哈,但奥马哈认为去米苏拉的最快路线是芝加哥,结果报文会在2个城市之间不停传来传去。如果看到某条消息的跳数很高,就知道路由肯定哪里错了。这叫”跳数限制“。
报文交换的缺点之一是有时候报文比较大,会堵塞网络,因为要把整个报文从一站传到下一站后才能继续传递其他报文。传输一个大文件时整条路都阻塞了,即便你只有一个1KB的电子邮件要传输,也只能等大文件传完,或是选另一条效率稍低的路线。解决方法是将大报文分成很多小块,叫”数据包“。就像报文交换,每个数据包都有目标地址,因此路由器知道发到哪里。报文具体格式由”互联网协议”定义,简称 IP 这个标准创建于 1970 年代,每台联网的计算机都需要一个IP地址。路由器会平衡与其他路由器之间的负载,以确保传输可以快速可靠,这叫”阻塞控制“。到达顺序可能会不一样,这对一些软件是个问题,但在 IP 之上还有其他协议,比如 TCP/IP, 可以解决乱序问题。
第 29 集 互联网
互联网由无数互联设备组成,而且日益增多。计算机为了获取网上的视频,首先要连到局域网,也叫 LAN。你家 WIFI 路由器连着的所有设备,组成了局域网。局域网再连到广域网,广域网也叫 WAN。WAN 的路由器一般属于你的”互联网服务提供商”,简称 ISP。广域网里,先连到一个区域性路由器,这路由器可能覆盖一个街区。然后连到一个更大的 WAN,可能覆盖整个城市。可能再跳几次,但最终会到达互联网主干。互联网主干由一群超大型、带宽超高路由器组成。
为了获取这个视频,数据包(packet)要先到互联网主干,沿着主干到达有对应视频文件的 YouTube 服务器。数据包从你的计算机跳到 Youtube 服务器,可能要跳个10次,先跳4次到互联网主干,2次穿过主干,主干出来可能再跳4次,然后到 Youtube 服务器。
数据包(packet)想在互联网上传输要符合”互联网协议”的标准,简称 IP。地址必须是独特的,并且大小和重量是有限制的。因为 IP 是一个非常底层的协议,数据包的头部(或者说前面)只有目标地址,头部存 “关于数据的数据”也叫 元数据(metadata)。但是不知道把包交给哪个程序,因此需要在 IP 之上,开发更高级的协议。这些协议里最简单最常见的叫”用户数据报协议”,简称 UDP。UDP 也有头部,这个头部位于数据前面,头部里包含有用的信息,信息之一是端口号,每个想访问网络的程序,都要向操作系统申请一个端口号。当一个数据包到达时,接收方的操作系统会读 UDP 头部,读里面的端口号,把数据包送到正确的程序。UDP 头部里还有”校验和“,用于检查数据是否正确,检查方式是把数据求和来对比。UDP中,”校验和”以 16 位形式存储 (就是16个0或1),如果算出来的和,超过了 16 位能表示的最大值,高位数会被扔掉,保留低位。当接收方电脑收到这个数据包,把所有数据加在一起,89+111+33… 以此类推,如果结果和头部中的校验和一致代表一切正常。如果不一致,数据肯定坏掉了,但 UDP 不提供数据修复或数据重发的机制,接收方知道数据损坏后,一般只是扔掉。发送方发了之后,无法知道数据包是否到达目的地,但是有些程序不在意这些问题,因为 UDP 又简单又快。
如果”所有数据必须到达”就用”传输控制协议“,简称 TCP。TCP 和 UDP 一样,头部也在存数据前面,包括这二者在内的一系列协议被称为TCP/IP协议族。就像 UDP ,TCP 头部也有”端口号”和”校验和”,但 TCP 有更高级的功能。其中重要的几个:
- TCP 数据包有序号,15号之后是16号,16号之后是17号,以此类推 发上百万个数据包也是有可能的。序号使接收方可以把数据包排成正确顺序,即使到达时间不同。
- TCP 要求接收方的电脑收到数据包并且”校验和”检查无误后(数据没有损坏)给发送方发一个确认码,代表收到了。”确认码” 简称 ACK 得知上一个数据包成功抵达后,发送方会发下一个数据包。假设这次发出去之后,没收到确认码那么肯定哪里错了。如果过了一定时间还没收到确认码发送方会再发一次,注意:数据包可能的确到了,只是确认码延误了很久,或传输中丢失了。但这不碍事,因为收件方有序列号,如果收到重复的数据包就删掉。TCP可以同时发多个数据包,收多个确认码,这大大增加了效率,不用浪费时间等确认码。确认码的成功率和来回时间可以推测网络的拥堵程度。TCP 用这个信息,调整同时发包数量,解决拥堵问题。简单说,TCP 可以处理乱序和丢失数据包,丢了就重发,还可以根据拥挤情况自动调整传输率。
TCP 最大的缺点是那些”确认码”数据包把数量翻了一倍,但并没有传输更多信息。有时候这种代价是不值得的,特别是对时间要求很高的程序,比如在线射击游戏。
当计算机访问一个网站时需要两个东西:1.IP地址 2.端口号,例如172.217.7.238 的 80 端口,这是谷歌的 IP 地址和端口号。输到浏览器里,然后就会进入谷歌首页。就像专为互联网的电话簿,它叫”域名系统“,简称 DNS。互联网有个特殊服务负责把域名和 IP 地址一一对应,显然 google.com 比一长串数字好记。在浏览器里输 youtube.com 浏览器会去问 DNS 服务器,它的 IP 地址是多少。一般 DNS 服务器是互联网供应商提供的,DNS 会查表,如果域名存在,就返回对应 IP 地址。然后浏览器会给这个 IP 地址发 TCP 请求来建立连接,如今有三千万个注册域名,所以为了更好管理,DNS 不是存成一个超长超长的列表,而是存成树状结构。顶级域名(简称 TLD)在最顶部,比如 .com 和 .gov,下一层是二级域名,比如 .com 下面有 google.com 和 dftba.com,再下一层叫子域名,比如 images.google.com, store.dftba.com,”三千万个域名”只是二级域名不是所有子域名。这些数据散布在很多 DNS 服务器上,不同服务器负责树的不同部分。
线路里的电信号,以及无线网络里的无线信号,这些叫”物理层“。而”数据链路层“负责操控”物理层”,数据链路层有:媒体访问控制地址(MAC),碰撞检测,指数退避,以及其他一些底层协议,再上一层是”网络层“:(IP)负责各种报文交换和路由,”传输层“比如 UDP 和 TCP 这些协议,负责在计算机之间进行点到点的传输,而且还会检测和修复错误。”会话层“使用 TCP 和 UDP 来创建连接,传递信息,然后关掉连接。查询 DNS 或看网页时,就会发生这一套流程。这是 开放式系统互联通信参考模型(OSI) 的底下5层。这个概念性框架把网络通信划分成多层,每一层处理各自的问题,如果不分层直接从上到下捏在一起实现网络通信,是完全不可能的。OSI 模型还有两层,”表示层”和”应用程序层”,其中有浏览器,Skype,HTML解码,在线看电影等。
第 30 集 万维网
万维网(World Wide Web)和互联网(Internet)不是一回事,万维网在互联网上运行,互联网是传递数据的管道,各种程序都会用,其中传输最多数据的程序是万维网,分布在全球数百万个服务器上,可以用”浏览器”来访问万维网。
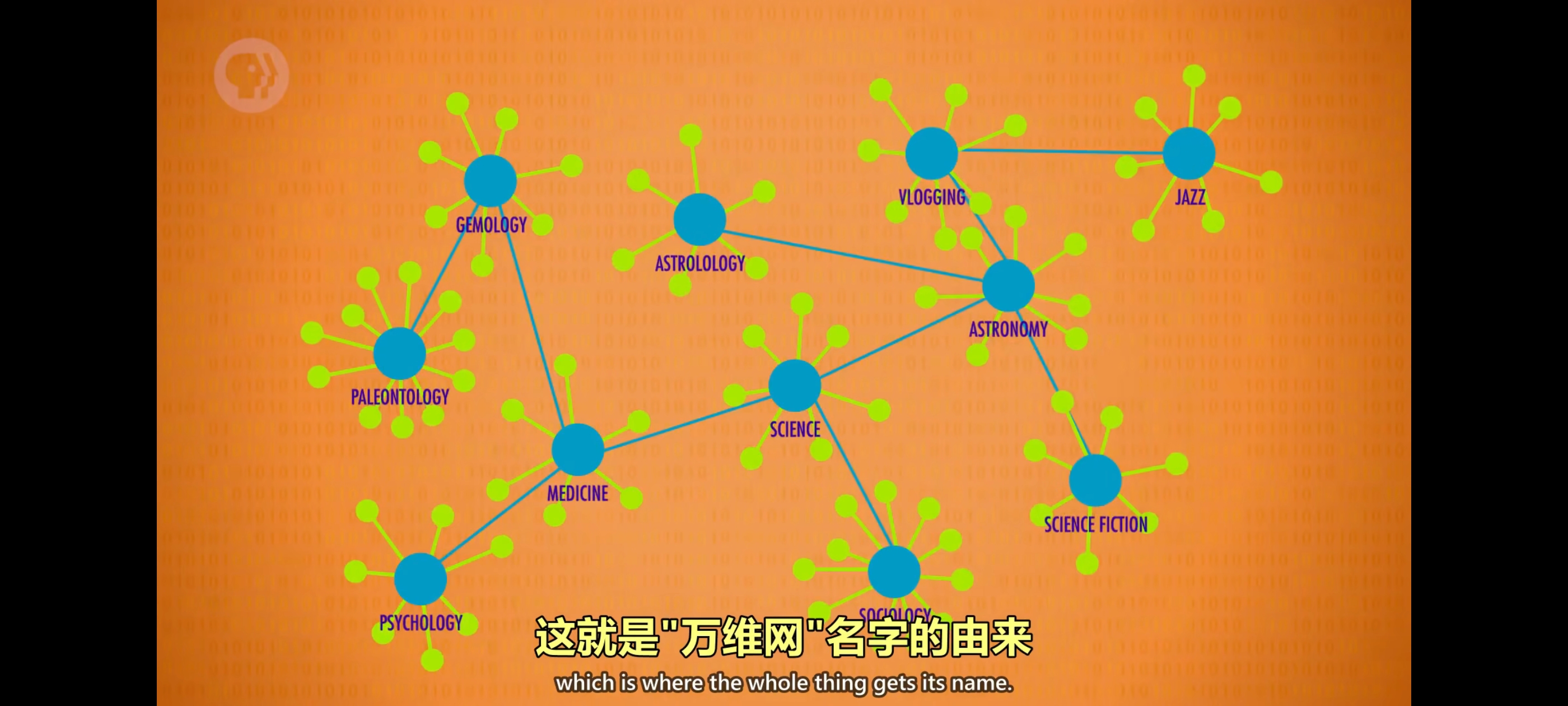
万维网的最基本单位,是单个页面,页面有内容,也有去往其他页面的链接 ,这些链接叫”超链接“。

这些超链接形成巨大的互联网络,这就是”万维网”名字的由来。
现在说起来觉得很简单,但在超链接做出来之前,计算机上每次想看另一个信息时,你需要在文件系统中找到它或是把地址输入搜索框,有了超链接,你可以在相关主题间轻松切换。因为文字超链接是如此强大,它得到了一个同样厉害的名字:”超文本“。如今超文本最常指向的,是另一个网页然后网页由浏览器渲染。为了使网页能相互连接,每个网页需要一个唯一的地址,这个地址叫 “统一资源定位器“,简称 URL。一个网页URL的例子是 “thecrashcourse.com/courses”。
当你访问一个网站时计算机首先会做”DNS查找”,DNS 会输出对应的IP地址,有了IP地址浏览器会发送 TCP 请求连接到这个 IP 地址,这个地址运行着”网页服务器”。网页服务器的标准端口是 80 端口,你的计算机连到了 thecrashcourse.com 的服务器,下一步是向服务器请求”courses”这个页面,这里会用”超文本传输协议“(HTTP)。HTTP的第一个标准,HTTP 0.9,创建于1991年,只有一个指令,”GET” 指令。我们向服务器发送指令:”GET /courses”,该指令以”ASCII编码”发送到服务器,服务器会返回该地址对应的网页,然后浏览器会渲染到屏幕上。如果用户点了另一个链接,计算机会重新发一个GET请求,你浏览网站时,这个步骤会不断重复。在之后的版本,HTTP添加了状态码,状态码放在请求前面。
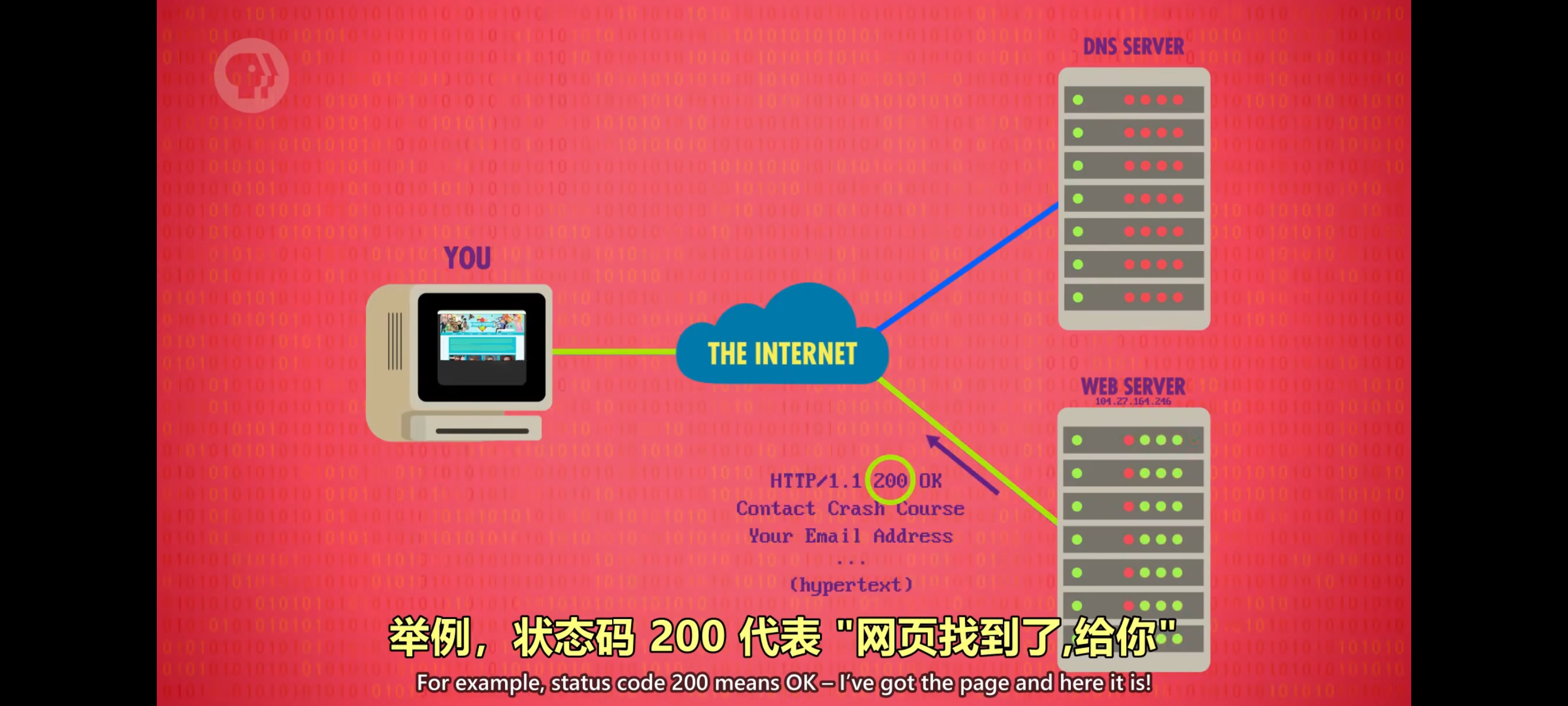
举例,状态码 200 代表 “网页找到了,给你”,状态码400~499代表客户端出错,比如网页不存在,就是可怕的404错误。
“超文本”的存储和发送都是以普通文本形式,如果只有纯文本无法表明什么是链接,什么不是链接,所以有必要开发一种标记方法,因此开发了超文本标记语言(HTML)。HTML 第一版的版本号是 0.8,创建于 1990 年,有18种HTML指令。

如今的网页更复杂一些,最新版的 HTML,HTML5,有100多种标签,图片标签,表格标签,表单标签,按钮标签等等,还有其他相关技术比如 层叠样式表 (CSS)和 JavaScript。
随着万维网日益繁荣,人们越来越需要搜索,如果你知道网站地址比如 ebay.com,直接输入浏览器就行,但不知道呢?起初人们会维护一个目录,链接到其他网站,其中最有名的叫”Jerry和David的万维网指南”,1994年改名为Yahoo。随着网络越来越大,人工编辑的目录变得不便利,所以开发了搜索引擎。
长的最像现代搜索引擎的最早搜素引擎,叫JumpStation,由Jonathon Fletcher于1993年在斯特林大学创建。它有 3 个部分,第一个是爬虫,一个跟着链接到处跑的软件,每当看到新链接,就加进自己的列表里,第二个部分是不断扩张的索引,记录访问过的网页上,出现过哪些词,最后一个部分,是查询索引的搜索算法。早期搜索引擎的排名方式非常简单,取决于搜索词在页面上的出现次数。谷歌成名的一个很大原因是创造了一个聪明的算法来规避这个问题,与其信任网页上的内容,搜索引擎会看其他网站有没有链接到这个网站。这些”反向链接”的数量,特别是有信誉的网站,代表了网站质量。Google 一开始时是 1996 年斯坦福大学一个叫 BackRub 的研究项目,两年后分离出来,演变成如今的谷歌。
“网络中立性“是应该平等对待所有数据包,不论这个数据包是我的邮件,或者是你在看视频,速度和优先级应该是一样的,但很多公司会乐意让它们的数据优先到达。节流(Throttled) 意思是故意给更少带宽和更低优先级。”网络中立性”的影响十分复杂而且广泛,这场争辩还会持续很久。